Summary
1. Oracle은 사용자의 요구를 DBMS에 전달하는 기능을 하는 인스턴스(Instance)와 데이터를 저장하고 데이터에 접근하는 대상인 데이터베이스(Database)로 구성되어 있다.
2. Oracle의 Instance는 정적으로(static) 메모리의 일정 공간을 차지하며 데이터베이스 사용자들에게 정보를 제공하는 SGA(System Global Area)와 데이터베이스 시스템의 운영을 담당하는 Oracle 프로세스로 구성된다.
3. Oracle 데이터베이스 서버는 자주 사용하는 데이터를 메모리에 오래 저장하여 I/O 효율을 높이고, 자주 사용하지 않는 데이터는 데이터 파일에 물리적으로 저장하여 한정된 SGA 영역을 효율적으로 관리한다. 이를 LRU(Least Recently Used) 알고리즘 이라 한다.
4. Oracle 데이터베이스 10g는 자동화된 공유 메모리 관리 기능이 있어 SGA의 메모리 관리를 쉽게 할 수 있다. 데이터베이스 관리자는 SGA_TARGET이라는 초기화 파라미터를 이용하여 Instance에서 사용 가능한 SGA 메모리의 전체 양을 정한다. 그러면 Oracle 데이터베이스는 가장 효율적으로 메모리를 사용할 수 있도록 자동으로 메모리를 분배한다.
5. 하나의 데이터베이스에는 하나 이상의 테이블스페이스를 가진다. SYSTEM, SYSAUX 테이블스페이스는 데이터베이스가 생성될 때 반드시 존재한다. 데이터베이스 운영에 필수적인 정보들을 가지고 있기 때문이다. 하나의 테이블스페이스는 여러 세그먼트들로 구성 된다. 112Kbytes 크기의 Segment 내에는 28Kbytes와 84Kbytes 크기의 Extent가 존재한다. 그리고 이들 Extent는 2Kbytes 크기의 여러 블록들이 존재한다. Block은 데이터를 저장하는 최소 단위이다. 이 Block에 Oraccle은 데이터베이스 객체와 데이터를 저장한다.
6. 테이블 데이터베이스 객체인 테이블이 두 개의 파일에 걸쳐서 표현되었는데, 이는 데이터 파일에 저장되는 데이터베이스 객체가 물리적인 데이터 파일의 영역이 아닌 테이블스페이스의 논리적인 저장영역 형태로 영역을 할당 받는다는 것을 나타내고 있다. 이는 Oracle 데이터베이스가 그 데이터 저장 및 관리를 논리적인 테이블스페이스로 하고 있다는 것을 말한다.
7. 컨트롤 파일은 데이터베이스의 물리적인 구조 정보를 가지고 있어서 데이터베이스가 시작될 때나 데이터베이스 복구할 때 항상 참조하는 파일이다.
8. 데이터베이스의 모든 변경 정보를 원본과 함께 저장하는 SGA 내의 리두 로그 버퍼의 정보를 메모리 영역이 아닌 물리적인 파일 형태로 Oracle 데이터베이스가 가지고 있는 것이 온라인 리두 로그 파일(On-Line Redo Log File)이다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Oracle Instance(오라클 인스턴스)
건설 현장(메모리 영역)에서는 현장 노동자(프로세스)들이 아침부터 부산히 움직인다. 현장의 다른 한 곳에는 여러 자재(데이터)들이 쌓여 있는 모습을 볼 수 있다.
사용자의 요구를 DBMS에 전달하는 기능을 하는 인스턴스(Instance)와 데이터를 저장하는 데이터베이스(Database)로 구성되어 있다.
사용자 <-------------> 인스턴스 <-------------> 데이터베이스
Oracle의 Instance는 정적으로(static) 메모리의 일정 공간을 차지하며, 데이터베이스 사용자들에게 정보를 제공하는 SGA(System Global Area)와 데이터베이스 시스템의 운영을 담당하는 Oracle 프로세스로 구성된다.
Oracle 데이터베이스 서버가 시작되면 SGA(System Global Area)와 1개 이상의 Oracle 프로세스가 활성화되는데, Oracle의 Instance는 SGA와 Oracle 프로세스들을 말합니다. Oracle은 다수 사용자의 요구 사항을 처리하기 위해 시스템으로부터 메모리를 요구한다. 그리고 할당받은 메모리 영역에 현재 사용 중인 프로그램 코드를 저장하거나 여러 사용자 간의 데이터를 공유하게 된다.
SGA(System Global Area: 시스템 공유 영역)
SGA는 Oracle이 시스템으로부터 자원을 할당 받아 관리하는 Oracle 시스템 영역이다. 데이터 베이스의 Instance가 시작되면 시스템으로부터 자원을 할당 받고, 데이터베이스 Instance가 종료되면 할당 받은 자원을 시스템에 반환한다. 즉, Instance가 시작된다는 것은 메모리의 일부를 SGA의 영역으로 할당 받고, CPU로부터 PROCESS 자원도 할당 받았음
Oracle 데이터베이스 서버는 자주 사용하는 데이터를 메모리에 오래 저장하여 I/O 효율을 높이고, 자주 사용하지 않는 데이터는 데이터 파일에 물리적으로 저장하여 한정된 SGA 영역을 효율적으로 관리한다. 이를 LRU(Least Recently Used) 알고리즘이라고 한다.
MRU(Most Recently Used) End는 가장 최근에 접근한 버퍼 영역으로 주로 데이터를 검색할 때 이용한다.
반면 LRU(Least Recently Used) End는 가장 이전에 접근한 버퍼 영역으로 주로 Free Buffer를 검색할 떄 이용한다.
Free Buffer는 아무것도 저장되어 있지 않은 버퍼 영역이다.
Pinned Buffer는 현재 액세스 되고 있는 데이터를 저장하고 있는 버퍼 영역을 말한다.
Dirty Buffer는 변경된 데이터를 저장하고 있는 버퍼 영역으로, Write list로 옮겨지게 된다.
하나의 시스템 내에서의 모든 프로세스는 균등하게 자원을 할당 받아 사용할 수 있어야 한다. 같은 시간에 한정된 시스템 자원을 요청한 프로세스들은 요청한 시간 별로 우선순위를 두어 그 자원의 사용권을 할당해야 한다. 이러한 시스템 내부의 알고리즘을 Aging 이라 한다.
사용자 프로세스의 요청으로 Oracle 서버 프로세스는 데이터베이스 버퍼 캐시를 읽게 되는데, 여기서 읽은 데이터베이스 버퍼를 MRU End에 이동시킨다. 그리고 다른 버퍼들은 aging 되게 하여 LRU End쪽으로 계속해서 이동이 된다. 결국 자주 사용되는 데이터는 오래도록 메모리에 보존하고 그렇지 못한 데이터는 aging 되어 데이터 파일에 저장하게 된다. 이러한 알고리즘을 통해 Oracle은 한정된 시스템 메모리를 효율적으로 관리한다.
System Global Area
| Java Pool | Buffer Cache | Redo Buffer |
| Streams Pool | Streams Pool | Large Pool |
데이터베이스 버퍼 캐시(DATABASE BUFFER CACHE)
Oracle 서버에 접속한 사용자들이 데이터를 요청하면 서버 프로세스는 데이터베이스 버퍼 캐시를 먼저 확인한다. 그래서 요청한 데이터가 있으면 데이터베이스 버퍼 캐시로부터 데이터를 읽어 반환한다. 만약 없다면 데이터 파일로부터 해당 데이터를 읽어 데이터베이스 버퍼 캐시에 저장한 후 요청한 데이터를 돌려주게 된다. 이때 디스크 I/O가 발생하면서 데이터베이스 성능을 저하시킨다. 따라서 가능한 디스크 I/O로부터 발생하는 성능 저하를 피하기 위해서는 항상 적당한 크기의 데이터베이스 버퍼 캐시가 필요하게 된다.
데이터베이스 버퍼 캐시는 메모리 내에서는 수정되었지만 아직 디스크에 기록되지 않은 dirty buffer로 구성된 write list와 LRU list로 구성되어 있다. LRU list는 사용할 수 있는 버퍼들인 free buffer들과 현재 사용 중인 버포로 구성된 pinned buffer, 그리고 저장이 필요한 수정된 버퍼들로 구성된 dirty buffer로 이루어져 있다.
데이터베이스 버퍼 캐시 메모리 영역에 저장되거나 변경된 데이터들은 LRU 알고리즘에 의해 버퍼 캐시에 보존되며, dirty buffer가 되어 write list로 이동하게 된다. 그리고 한정된 데이터베이스 버퍼 캐시 내에서 서버 프로세스가 더 이상 free buffer들을 찾을 수 없을 때 DBW0 프로세스에 신호를 보내게 된다. 그러면 DBWR 프로세스는 write list의 dirty buffer들을 데이터 파일에 저장한다.
공유 풀 영역(SHARED POOL AREA)
공유 풀은 사용자가 작성한 SQL문이 저장되어 관리되는 곳이다.
CONN hr
SELECT *
FRO employees;표준 SQL 문법과 다른경우 다음과 같이 에러가 나타난다.
ORA-00923: FROM keyword not found where expected
CONN hr
SELECT *
FROM emp;hr 사용자가 질의할 수 있는 사원 테이블(emp)이 존재하지 않는다면 아래와 같은 오류를 발생한다.
ORA-00942: table or view does not exist
CONN hr
SELECT *
FROM SCOT.DEPT;SCOTT이 소유한 부서 테이블(dept)에 접근할 수 있는 권한이 없는 경우 아래와 가이 오류를 발생시킨다.
ORA-00942: table or view does not exist
SQL문을 Library Cache(라이브러리 캐시) 내에 저장한다. 왜냐하면, 동일한 SQL문이 다시 실행될 때 확인된 SQL문을 이용하기 위해서다. 가능한 공유 풀에 저장된 SQL문을 활용하여 처리하는 것이 성능을 향상하는 방법이다.
아래 질의문은 동일 결과를 출력하지만 Oracle은 서로 다른 문장으로 생각한다. (대소문자도 같아야지 같은문자)
SELECT ename FROM emp
select ename from emp
SELECT ename FROM emp리두 로그 버퍼(REDO LOG BUFFER)
리두 로그 버퍼는 데이터베이스 장애 발생 시 복구를 위해 모든 변경된 정보와 원래의 원본 정보들을 저장하는 버퍼이다. 리두 로그 버퍼는 지정된 크기만큼의 데이터를 메모리에 저장하고 있다가 이를 온라인 리두 로그 파일에 저장한다.
리두 로그 버퍼의 크기가 크다면 메모리 상에서 데이터를 보유할 수 있는 가능성이 크므로, 온라인 리두 로그 파일의 I/O를 줄일 수 있다. 그만큼 복구 시간을 최소화할 수 있다는 것이다.
데이터베이스 버퍼 캐시 내의 데이터는 트랜잭션(Transaction)에 의해 데이터가 변경되어도 곧바로 저장되지 않는다. 천재지변이나 정전 등의 사고가 발생하여 데이터베이스가 비정상적으로 종료되었다면, 데이터베이스 버퍼 캐시 안의 저장되지 않은 변경 데이터는 리두 로그 파일에 의존하여 비정상적으로 종료된 시점까지 복구할 수 있게 된다.
예전에는 DBA가 초기화 파라미터의 값을 통해 SGA를 구성하는 각 요소의 크기를 지정해 주었다. 예를들면 DBA가 SHARED_POOL_SIZE, DB_CACHE_SIZE에 각각 값을 할당해 주었다. 그러나 Oracle 데이터베이스 10g는 자동화된 공유 메모리 관리 기능이 있어 SGA의 메모리 관리를 쉽게 할 수 있도록 지원한다.
DBA는 SGA_TARGET이라는 초기화 파라미터를 이용하여 Instance에서 사용 가능한 SGA 메모리의 전체 크기를 정한다. 그러면 Oracle DB는 가장 효율적으로 메모리를 사용할 수 있도록 SGA에 할당된 전체 크기로부터 자동으로 메모리를 분배한다.
과거 수동으로 SGA를 설정할 때는 Compile된 SQL문이 SHARED POOL로부터 적절하지 않은 크기 때문에 종종 Age Out 되었다. 이는 잦은 Parsing 작업을 일으키게 되고, 그에 따른 데이터베이스 성능 저하를 발생시켜 왔다. 그러나 자동 SGA 관리를 통해 내부 튜닝 알고리즘이 작업의 부하를 모니터링 함으로써 적절한 SGA의 크기를 유지할 수 있는 것이 가능해 졌다.
데이터베이스가 시작되면 동적으로 SGA_TARGET은 크기를 늘리거나 줄인다. 그러나 SGA_MAX_SIZE의 값을 초과하지는 않는다.
CONN system
SHOW PARAMETER SGA_MAX_SIZE| NAME | TYPE | VALUE |
| sga_max_size | big integer | 164M |
Oracle Enterprise Manager URL:
http://localhost:1158/em - SYSDBA
SYS 사용자로 Login 하면 화면 아래 관령 링크에서 '중앙 권고자(Advisor Central)' 항목을 클릭한다.
화면 가운데 '메모리 권고자(Memory Advisor)'를 클릭한다.
자동으로 데이터베이스가 공유 메모리를 관리하기 원한다면 자동 공유 메모리 관리 활성화 버튼을 눌른다.
총 SGA 크기를 지정하면 자동 공유 메모리가 활성화된 경우 데이터베이스는 SGA 구성 요소 간 최적의 메모리 분배량을 자동으로 설정하게 된다.
- SHARED POOL (SQL, PL/SQL 실행할 때)
- JAVA POOL (JAVA 실행할 때)
- LARGE POOL (RMAN BACKUP BUFFER)
- BUFFER CACHE
DBA는 위 요소의 크기를 명시적으로 정의할 필요가 없다. 기본적으로 이들 파라미터의 값은 0이다.
SGA를 구성하는 각 요소가 메모리를 요구하면 내부 자동 튜닝 메커니즘에 의해 메모리가 할당된다. Instance는 내부 View나 통계 정보를 이용하여 위 요소간에 어떻게 메모리를 분배할 것인지 결정한다. 서버 파라미터 파일(SPFile)을 사용하고 있다면 Oracle DB는 Instance 종료(SHUTDOWN)시 자동으로 조율된(tuned) 요소들의 크기를 기억해둔다. 나중에 Instance가 시작하면 과거 Instance의 정볼르 활용하여 지속적으로 작업의 부하를 평가한다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Program Global Area(PGA)
PGA란 프로세스들이 공유하여 사용할 수 있는 SGA와는 달리, 개별 프로세스들이 독립적으로 사용하는 비 공유 메모리 영역으로, 서버 프로세스를 위한 데이터와 제어 정보를 저장한다.
PGA는 서버 프로세스가 시작할 때 Oracle에 의해 생성된다. PGA의 총 크기는 Oracle Instance에 속한 각 프로세스에 의해 할당된다. PGA는 개별 세션에 대한 바인드 변수(Bind Variable) 정보, SORT AREA, 커서(CURSOR) 처리 등의 작업을 할 떄 서버 프로세스를 돕는 역활을 한다.
바인드 변수(Bind Variable)
아래 SQL문은 서로 다른 부서 아이디(department_id)로 인해 SQL문이 일치하지 않아 두 번의 Parsing 작업이 일어나는 예이다.
SELECT employee_id FROM employees WHERE department_id = 10;
SELECT employee_id FROM employees WHERE department_id = 20;아래와 같이 상수 값을 바인드 변수로 변환한다면, SQL문이 재사용되어 한 번만 Parsing되므로 성능을 향상시킨다.
SELECT employee_id FROM employees WHERE department_id = :dept_id;바인드 처리가 된 SQL문은 다시 Parsing 하지 않고, 개별 세션에 저장된 실제 값을 바인드 변수에 대체하게 한다. 즉 SQL문을 재사용함으로써 SQL문이 실행될 때마다 Parsing되는 것을 방지하여, 공유 풀과 라이브러리 캐시 등과 같은 시스템 자원 사용량을 감소시켜 성능향상을 가져온다.
SORT_AREA
정렬(SORT)이 필요한 작업은 SORT_AREA를 사용하여 정렬 작업의 속도를 향상시킨다. 만약 처리되어야 할 데이터 양이 SORT_AREA보다 크면 정렬 대상이 되는 데이터는 보다 작은 조각으로 나누어진다. 이렇게 나누어진 데이터 조각들은 메모리에서 처리되는 것이 가능하며, 후에 처리될 남은 조각들은 임시 데이터 영역에 저장된다.
아래 질의를 통해 DB에 설정된 파라미터 SORT_AREA_SIZE의 값을 확인할 수 있다.
CONN system
SHOW PARAMETER SORT_AREA_SIZE| NAME | TYPE | VALUE |
| sort_area_size | integer | 65536 |
SORT_AREA_SIZE 크기가 64Kbytes임을 나타내고 있다.
SORT_AREA는 제어되며 조율되어 일반적으로 대용량의 DB에서 높은 메모리 소비 비용을 요구하는 특정 작업에 대한 성능을 향상시킨다.
커서 처리
애플리케이션 개발자는 프로그램의 실행을 통해 명시적으로 커서를 열거나 Private SQL 영역을 사용할 수 있다. 즉 Private SQL 영역의 할당(allocation)과 반납은 User Process와 관련이 있다는 것이다. User Process가 할당할 수 있는 Private SQL 영역은 초기화 파라미터 OPEN_CURSORS에 의해 제한된다. 기본값은 50 이다.
아래 질의를 통해 DB에 설정된 파라미터 OPEN_CURSOR의 값을 확인할 수 있다.
CONN system
SHOW PARAMETER OPEN_CURSOR| NAME | TYPE | VALUE |
| open_cursors | integer | 300 |
Private SQL 영역은 CURSOR가 닫혀질 떄까지 존재한다. 애플리케이션 개발자는 명시적으로 커서를 선언한 뒤 사용하지 않은 모든 열린 커서를 닫음으로써 메모리의 사용량을 최소화해야 한다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
프로세스(Process)
Oracle Instance를 구성하는 또 하나의 부분이 프로세스이다. DB시스템 운영을 담당하고있는 프로세스 종류를 살펴보고, 각 프로세스의 역활을 통해 Oracle의 메모리 영역과 파일 간에 프로세스들이 어떻게 상호 작용하는지 확인해본다.
사용자 프로세스(User Process)
사용자 프로세스는 애플리케이션 프로그램의 실행으로 발생하며, 클라이언트 프로세스라고도 한다. Oracle은 클라이언트 프로세스가 발생하여 특정 요구를 하게 되면 서버 프로세스를 생성하는데, 이때 생성된 Oracle 서버 프로세스는 클라이언트 프로세스와 통신하며 클라이언트의 요구사항을 처리한다.
서버 프로세스(Server Process)
Oracle 서버 프로세스는 사용자가 Oracle DB 서버에 접속하였을 때 서버 프로세스 모드 별로 전용(Dedicated) 모드일 때는 PGA에, 공유(Shared) 모드일 때는 SGA에 클라이언트의 세션 정보를 저장한다.
사용자 프로세스의 요구사항을 처리하는 서버 프로세스는 전용 서버 모드와 공유 서버 모드가 있다. 'dedicate'라는 어휘의 사전적인 뜻을 찾아보면 '헌신적인' 이라는 의미를 얻을 수 있다. User Process에 대해 1:1로 Server Process가 대응하여 동작한다는 것이다. 서버 프로세스는 유저 프로세서의 세션이 종료하기 전까지 헌신적으로 일을 처리한다. 만약 아무런 일을 하지 않은 채 유저 프로세스가 세션만을 유지하고 있더라도 서버 프로셋는 다른 사용자의 요구는 관심도 없이 오직 자신에게 할당된 요구만을 기다리고 있다.
하나의 사용자 프로세스당 하나의 서버 프로세스가 대칭이 되어 작업하는 모드로, 배치 작업이나 백업/복구 등의 대용량 데이터를 처리할 때 주로 설정되어 사용된다.
'shared'는 '공유한다' 는 의미가 있다. 앞서 Dedicated Server처럼 유저 프로세서의 요구 사항을 어느 특정 서버 프로세스가 맡아 일 처리를 하는 것이 아니란 것이다. 즉 현재 작업을 하지 않는 서버 프로세서라면 누구나 유저 프로세서의 요구 사항을 처리할 수 있는 것이다.
클라이언트 프로세스가 요청하면 서버 프로세스가 아닌 디스패처(Dispatcher) 프로세스와 접속하여 작업이 이루어진다. 'dispatch' 의 사전적인 의미는 '발송하다', '급파하다' 의 의미가 있다. 무엇인가를 전달하는 역활을 하는데 여기서는 클라이언트의 요구 사항을 전달하는 역활이다.
디스패처 프로세스는 동시에 여러 개의 클라이언트 프로세스와 작업이 가능하다. 클라이언트의 요구가 있을 때 디스패처는 SGA 내의 요청 대기 열(Request Queue)에 클라이언트의 요구를 저장한다. 그러면 오라클 서버 프로세스는 요청 대기열의 내용을 차례대로 처리하여 응답 대기 열(Response Queue)에 담아둔다. 이를 다시 디스패처 프로세스가 응답 대기 열에 담긴 내용들을 차례대로 클라이언트 프로세스에게 돌려주게 된다.
정리하면 이 모드에서는 다수의 클라이언트 프로세스들이 서버 프로세스들을 공유하므로 시스템 자원을 보다 효율적으로 사용할 수 있다.
백그라운드 프로세스(Background Process)
데이터베이스 성능을 최대화하고 많은 사용자의 요구를 처리하기 위해 오라클은 '백그라운드 프로세스'라는 여러 프로세스를 사용한다. 백그라운드 프로세스들은 오라클 인스턴스가 시작하면 자동으로 생성된다.
1. Database Writer (이하 DBWn)
'Database Writer'의 의미를 해석하면 '데이터베이스에 쓴다.', '데이터 파일에 기록한다.'라는 의미를 연상할 수 있다. 즉, DBWn은 데이터베이스 버퍼로부터 읽어들인 블럭의 내용을 데이터 파일에 쓰는 역활을 한다.
버퍼의 내용은 시스템이 사용 중일 때 기록되지만, 데이터베이스가 종료하거나 비정상적으로 시스템이 종료되면 모든 내용을 잃어버리기 떄문에 적절한 시점에서 데이터 파일에 저장하는 것이 필요하다.
초기화 파라미터 DB_WRITER_PROCESSES는 DBWn 프로세스의 수를 정의한다. 최대 DBWn 프로세스의 수는 20이다. 만약 정의되지 않았다면 DB가 시작할 때 오라클은 CPU와 프로세스 그룹의 수에 의해 DB_WRITER_PROCESSES의 값을 설정한다.
CONN system
SHOW PARAMETER DB_WRITER_PROCESSES| NAME | TYPE | VALUE |
| db_writer_processes | integer | 1 |
2. Log Writer (이하 LGWR)
'Log Writer'의 의미를 해석하면 '로그에 쓴다.', '로그파일에 기록한다.' 라는 의미를 연상할 수 있다. 즉 LGWR는 리두 로그 버퍼로부터 읽어 들인 블록의 내용을 리두 로그 파일에 쓰는 역활을 한다.
사용자 프로세스에 의해 트랜잭션이 발생하였다. 그러면 서버 프로세스는 DB 버퍼 캐시 상의 원본 데이터와 변경된 데이터의 복사본을 리두 로그 버퍼에 저장해 두게 된다. 그러면 LGWR 프로세스는 리두 로그 버퍼에 기록된 내용을 온라인 리두 로그 파일에 쓰는 일을 처리한다.
LGWR의 동작은 다음의 경우 발생한다.
- 사용자 프로세스에 의해 COMMITS 트랜잭션이 발생할 때
- 3초마다
- 리두 로그 버퍼가 1/3 기록되었을 때
- 체크 포인트가 발생했을 때
3. System Monitor(이하 SMON)
SMON은 시스템을 모니터링 한다. 만약 오라클 인스턴스를 구성하는 메모리 구조와 프로세스가 계속 실행될 수 없어 인스턴스가 실패하는 경우 인스턴스를 복구하는 역활을 한다. 또한, 작은 공간 조각을 모아 합치거나 연결해줌으로써 DB에서 디스크 공간을 관리하는 역활도 한다. 더는 사용하지 않는 임시 세그먼트들과 세션이 종료된 트랜잭션도 정리한다.
4. Process Monitor(이하 PMON)
PMON은 프로세스를 모니터링 한다. 즉 사용자 프로세스들이 올바로 동작하는가를 감시한다. 만약 어떤 이유로 사용자 프로세스가 오라클에 접속하는 과정에서 실패하면, PMON은 사용자의 나머지 작업을 삭제하며, 시스템에 수행한 모든 변경작업을 ROLLBACK하거나 DB에 대한 작업을 중단하여 원래 상태로 복구시키는 역활을 한다. 또한, 종료된 프로세스가 가지고 있는 LOCK을 풀어주고, 프로세스가 사용한 SGA 영역의 자원을 시스템에 되돌려 주는 역활도 한다.
5. Checkpoint(이하 CKPT)
CKPT는 설정된 시간에 DBWn에 신호를 보내어 SGA 내의 변경된 데이터들을 모두 데이터 파일에 기록하는 역활을 한다. 또한, DB를 구성하는 모든 데이터 파일들을 로그 시퀀스(Sequence) 번호를 데이터 파일 헤더와 컨트롤 파일에 쓰는 작업을 한다.
설정된 시간의 정보는 아래와 같이 확인할 수 있다.
CONN system
SHOW PARAMETER LOG_CHECKPOINT_TIMEOUT| NAME | TYPE | VALUE |
| log_checkpoint_timeout | integer | 1800 |
6. Archiver(이하 ARCn)
ARCn 프로세스가 동작하기 위해서는 데이터베이스가 아카이브 모드로 운영되고 있어야 한다. 만약 자동 아카이빙이 설정되어 있다면 Archiber는 로그 스위치 발생 후 지정된 위치로 온라인 리두 로그 파일의 복사본을 이동시키는 작업을 한다. 최대 10개까지 프로세스를 가질 수 있다.
conn sys as sysdba
archive log listDatabase log mode No Archive Mode
Automatic archival Disabled
Archibe destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 21
Current log sequence 23
현재 DB는 No Archive Mode이다. 즉 온라인 리두 로그 파일이 순환하면서 기록되다가 이전의 기록을 다시 엎어쓰는 상황을 예상할 수 있다. 예를 들어 Group #1 -> Group #2 -> Group #3 -> Group #1 순서로 순환하면서 기록을 하는데 이때 마지막 Group #1에 기록될 때는 최초 Group #1의 내용을 덮어쓰는 상태가 된다는 것이다.
Archive Process에 의한 자동 아카이브(Automatic Archival)는 지원하지 않는다. 자동 아카이브가 지원된다면 로그 시퀀스가 증가하여 17번이 되기 전에 14번 로그 시퀀스를 가지는 Group #1의 로그 파일의 내용을 Archive Process가 아카이브 파일에 저장해 둔다. 이때 저장된 아카이브 파일의 위치를 Archive Destination이 나타내고 있다.
그럼 DB를 아카이브 모드로 운영하려면 어떻게 해야 할까? Oracle Universal Installer에 의해 DB를 설치할 때 설정이 가능하다. 또한, Enterprise Manager에서도 설정이 가능하다.

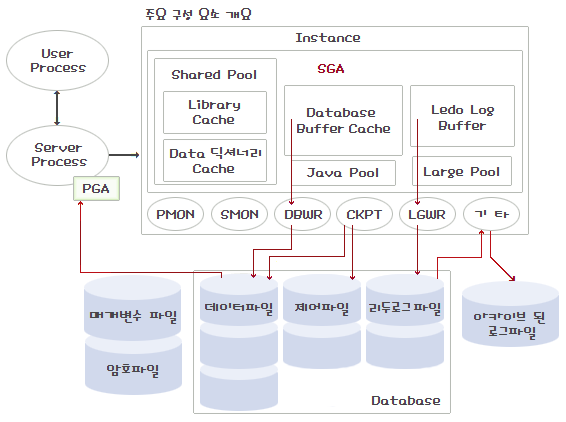
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
데이터 베이스
오라클은 사용자의 요구를 DBMS에 전달하는 기능을 담당하는 Instance와 데이터를 저장하고 데이터에 접근하는 대상인 데이터베이스(Database)로 구성되어 있음을 여러분은 알고있다.
'데이터베이스'는 데이터를 저장하는 저장 영역을 말한다. Oracle은 저장 영역인 데이터베이스를 효율적으로 사용하기 위해 논리적 데이터베이스와 물리적 데이터베이스로 구분하여 설명하고 있다.
논리적 데이터베이스 구조(Logical Database Structure)
오라클의 논리적 저장 구조는 디스크 사용 공간에 대해 보다 세밀한 설정을 가능하게 한다. 오라클 논리적 데이터베이스 구조에 대해 살펴보고 어떻게 저장 공간을 효율적으로 사용하는지 살펴보자.
데이터 블록(Data Block)
독자 여러분은 디스크의 검색 속도를 빠르게 하기 위해 데이터 조각 모음을 해 본 적이 있을 것이다. 오라클의 데이터 블록도 이와 같은 조각으로 생각하자.
Oracle 데이터 블록이란 오라클 데이터베이스 시스템이 데이터를 저장하는 가장 작은 논리적 단위이다.
오라클 데이터 블록은 데이터베이스를 생성할 때 결정되는 사항이므로 그 크기를 결정하는 것은 중요하다. 이 크기는 데이터베이스가 생성된 이후에는 다시 변경할 수 없음을 생각해야 한다. 즉 오라클 데이터 블록의 크기 결정은 APPLICATION에서의 데이터 Processing 환경에 따라 정해진다. 데이터 블록의 크기는 운영체제에 따라 다르지만 대개 2K ~ 16K(2,048bytes ~ 16,384bytes)이다.
APPLICATION이 OLTP의 데이터 Processing 환경일수록 작은 데이터 블록의 크기를, DSS(Decision Support System) 데이터 Processing 이면 큰 크기의 데이터 블록을 사용한다. 이는 OLTP 업무의 특성상 다수의 사용자에 의해 발생하는 트랜잭션을 처리하기 위해 작은 블록이 유리한 반면, DSS 업무는 읽기 위주의 작업을 빠르게 처리할 수 있도록 가능한 하나의 블록에 많은 데이터르 저장해 두는 것이 유리하기 떄문이다.
데이터 블록의 크기는 DB_BLOCK_SIZE의 값에 의해 결정된다. Oracle 9i에서부터 데이터베이스 레벨에서 관리되던 데이터 블록 크기를 테이블스페이스 레벨에서 관리할 수 있게 되었다. 따라서 DBA는 데이터베이스를 재생성하지 않고도, 테이블스페이스의 데이터베이스 블록 크기를 변경할 수 있게 되었다.
이와 같은 비표준 블록의 지원은 오라클 DB의 기능 중의 하나인 트랜스포터블 테이블스페이스(Transportable TABLESPACE)를 이용하여 작은 데이터 블록으로 사용되던 OLTP 데이터베이스의 특정 테이블스페이스를 큰 블록을 사용하는 DSS 데이터베이스에 통합할 떄 그 효용 가치를 가진다.
참고
Transportable TABLESPACE에 대해 좀 더 알고 가자.
Transportable TABLESPACE는 Oracle 데이터베이스 간에 대용량의 데이터를 이동하는 가장 빠른 길이다. 독자 여러분은 Transportable TABLESPACE을 사용하여 서로 다른 Machine Architecture나 운영체제에서 운영되는 Oracle 데이터 파일들을 한 데이터베이스에서 다른 데이터베이스로 직접 전송할 수 있다. 게다가 Transportable TABLESPACE는 Import와 Export처럼 데이터와 Metadata의 전송이 가능하다. 일반적으로 Transportable TABLESPACE는 운영 중인 DB에서 Data Warehouse로 혹은 Data Warehouse에서 Data Mart로 데이터를 이동할 떄 사용한다.
참고로 시스템 테이블스페이스 및 SEED DATABASE를 구성하는 초기 테이블스페이스들은 가변 블록이 적용되지 않고, 항상 처음 설정한 DB_BLOCK_SIZE의 값을 유지한다.
시스템에 설정된 DB_BLOCK_SIZE의 값은 아래와 같다.
CONN system
SHOW PARAMETER DB_BLOCK_SIZE| NAME | TYPE | VALUE |
| db_block_size | integer | 8192 |
익스텐드(Extent)
Extent는 데이터를 저장하기 위한 연속적인 데이터 블록의 집합이다. 예를 들어 어떤 사용자가 테이블을 생성하면 이를 저장하기 위해 데이터 블록이 할당된다. 이때 저장 공간을 연속된 블록들로 할당한다. 이때 처음 할당되는 블록들을 Initial Extent라 한다. 사용자의 데이터 추가 작업으로 저장 공간이 부족하게 되면, 새로운 데이터 블록이 필요하게 되어 오라클은 다시 연속적인 블록을 할당한다. 즉 오라클에서 Extent는 데이터가 할당되는 최소 단위가 된다.
예를 통해 오라클은 내부적으로 어떻게 EXTENT를 할당하고 있는지 살펴 보자.
CONN hr
CREATE TABLE test_extent (
NO NUMBER
);HR 계정으로 접속하여 TEST_EXTENT 테이블을 생성한다. 생성된 테이블이 저장되어야 하기때문에 저장 공간을 할당하는데 이 떄 EXTENT 크기로 저장 공간을 할당받는다.
SELECT TABLESPACE_NAME, BYTES
FROM USER_EXTENTS
WHERE SEGMENT_NAME = 'TEST_EXTENT';| TABLESPACE_NAME | BYTES |
| USERS | 65536 |
앞서 하나의 블록 크기가 8,182Bytes 이므로, 8개의 연속된 블록이 할당되었음을 알 수 있다.
CREATE OR REPLACE PROCEDURE increase_number
IS
i NUMBER := 0;
BEGIN
LOOP
INSERT INTO test_extent VALUES(i);
i := i + 1;
EXIT WHEN i = 1000000;
END LOOP;
END;
EXEC increase_number위에서 작성된 increase_number 저장 프로시저는 테이블 test_extent에 0에서 1씩 값을 증가시키면서 1,000,000행의 데이터를 추가하는 동작을 수행한다. 따라서 오라클은 내부적으로는 1,000,000개의 숫자 값을 저장하기 위한 저장 공간을 할당할 것이다. 생성된 저장 프로시저 increase_number를 실행한 후 아래 질의문을 실행해보자.
SELECT SUM(BYTES)
FROM USER_EXTENTS
WHERE SEGMENT_NAME = 'TEST_EXTENT';| SUM(BYTES) |
| 13631488 |
위 결과를 보면 1,3641,488Bytes(약 1.36Mbytes)의 저장 공간을 할당하고 1,000,000행의 데이터를 저장했음을 알 수 있다.
세그먼트(Segment)
세그먼트(Segments)의 사전적인 의미는 '조각, 단편' 입니다. 여기서 조각이란 테이블스페이스에 대한 조각으로 생각하자. 세그먼트는 테이블스페이스를 구성하는 논리적인 저장 단위이다. 또한 여러 Extent의 집합을 말한다.
Oracle은 데이터를 효율적으로 저장하기 위해 다양한 유형의 세그먼트들을 가진다.
데이터 세그먼트(Data Segments)
테이블, 클러스터 테이블, 구체화 뷰(materialized view)의 데이터를 저장하는 세그먼트이다. 사용자가 테이블에 데이터를 입력하면 그 데이터는 오라클 DB에서 데이터 세그먼트로 인식되며 관리된다. 세그먼트 형태 중 가장 빈번하게 I/O를 일으킨다.
인덱스 세그먼트(Index Segments)
테이블 데이터의 인덱스를 저장하는 세그먼트이다. 사용자가 인덱스를 생성하면 오라클 DB는 해당 인덱스의 정보를 인덱스 세그먼트에 저장한다.
롤백 세그먼트(Rollback Segments)
오라클 DB는 한 개 이상의 롤백 세그먼트를 가지고 있다. 롤백 세그먼트는 변경 이전(Before Image)의 값을 저장하여, 사용자들에게 데이터 일관성(Read Consistency)을 제공한다. 또한, 트랜잭션이 롤백(ROLLBACK)되면 저장하고 있는 이전의 데이터를 제공한다.
오라클 9i 이전에서는 트랜잭션의 단위 또는 그 크기에 따라 DBA가 수동으로 롤백 세그먼트를 생성하는 방식이었지만 Oracle 9i 이후에는 시스템에서 롤백 세그먼트를 자동으로 관리한다. 즉 더이상 DBA가 트랜잭션을 고려하여 롤백 세그먼트를 생성하지 않아도 된다.
이렇게 오라클 DB에서 롤백 세그먼틀르 자동으로 관리하는 것을 자동 언두 관리(Automatic Undo Management)라 부른다. 오라클 DB 시스템은 변경되기 이전의 언두 데이터를 언두 테이블스페이스에서 관리함으로써, 사용자가 COMMIT하여 이미 데이터베이스에 반영한 데이터도 원래의 값으로 되돌릴 수 있는 플래시백 질의(Flashback Query) 기능이 가능해진다.
오라클 DB는 Undo 정보를 이용하여 관리자 혹은 사용자가 과거 특정 시간의 데이터베이스 정보에 접근할 수 있게 한다. 이떄 Undo 정보를 위한 유보 기간은 Flashback 기능의 성공적인 실행을 위한 중요한 요소가 된다.
애플리케이션 개발자는 Flashback Query를 사용함으로써 사용자가 DBA의 개입을 최소화하면서 자신의 실수를 수정할 수 있다. 즉 DBA는 단지 적절한 크기의 UNDO TABLESPACE의 크기와 UNDO RETENTION 기간을 설정하기만 하면 된다. 오라클이 제공하는 DBMS_FLASHBACK 패키지는 세션 레벨에서 Flashback Query가 가능하도록 지원한다.
현재 설정된 UNDO RETENTION 설정
CONN system
SHOW PARAMETER UNDO_RETENTION| NAME | TYPE | VALUE |
| undo_retention | integer | 900 |
현재 설정된 UNDO TABLESPACE의 크기 73.4Mbytes 크기임을 나타내고 있다.
CONN system
SELECT TABLESPACE_NAME, BYTES
FROM DBA_DATA_FILES
WHERE TABLESPACE_NAME = 'UNDOTBS1';| TABLESPACE_NAME | BYTES |
| UNDOTBS1 | 73400320 |
독자 여러분은 AS OF절과 함께 SELECT절을 사용함으로써 Flaashback Query를 실행, 과거 특정 시점에 존재하는 데이터에 대한 조회를 할 수 있다. 이 질의는 TIMESTAMP를 이용하여 명시적으로 과거의 시간을 참조한다.
가. 'Tobias'의 사원 정보가 삭제되었다.
CONN hr
.
.
DELETE EMPLOYEES
WHERE last_name = 'Tobias';
.
.
COMMIT;나. 오후 2시 'Tobias'의 사원 정보가 삭제되었음을 확인한다.
.
.
SELECT *
FROM employees
WHERE last_name = 'Tobias';다. 오후 1시 50분 삭제된 'Tobias'의 사원 정보가 있음을 확인한다.
SELECT *
FROM employees
AS OF TIMESTAMP TO_TIMESTAMP('2022-10-10 13:50:00', 'YYY-MM-DD HH24:MI:SS')
WHERE last_name = 'Tobias';| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | PHONE_NUMBER | HIRE_DAT | JOB_ID | SALARY | |
| 117 | Sigal | Tobias | STOBIAS | 515.127.4564 | 97/07/24 | PU_CLERK | 2800 |
라. Flashback Query를 이용하여 잃어버린 데이터를 다시 추가한다.
INSERT INTO employees
(
SELECT *
FROM employees
AS OF TIMESTAMP TO_TIMESTAMP('2022-10-10 01:50:00', 'YYYY-MM-DD HH:MI:SS')
WHERE last_name = 'Tobias'
);
COMMIT;마. 추가된 'Tobias' 사원의 정보를 확인한다.
SELECT *
FROM employees
WHERE last_name = 'Tobias';
임시 세그먼트(Temporary Segments)
임시 세그먼트는 오라클의 SORT_AREA_SIZE에 할당된 메모리의 크기보다 큰 대용량의 데이터를 정렬할 때 사용하는 작업 공간이다.
서버에 설정된 메모리 내 정렬 SORT_AREA_SIZE를 넘는 용량의 데이터들은 임시 세그먼트에서 정렬을 마친 후 사용자 세션에 그 결과를 되돌려 준다. 이와 같이 하드웨어적인 I/O를 유발하는 작업은 OLTP 환경에서 성능을 저하시키는 원인이 되므로, 데이터베이스 관리자는 현재 운영 중인 시스템에 맞도록 SORT_AREA-SIZE를 계산하여 최대한 메모리 내에서 정렬작업이 이루어지도록 설정해야 한다.
사용자가 아래와 같은 작업을 수행하였을 떄 정렬 작업이 요구된다.
- CREATE INDEX ~
- SELECT ~ ORDER BY
- SELECT DISTINCT ~
- SELECT ~ GROUP BY
- SELECT ~ UNION
- SELECT ~ INTERSECT
- SELECT ~ MINUS
- 인덱스 되지 않은 테이블 내 데이터의 JOIN
정리하면 이들 작업을 수행할 때 가능한 메모리에서 정렬 작업이 수행할 수 있도록 하는 것이 데이터베이스 성능에 효과적이라 할 수 있다.
테이블스페이스(TABLESPACE)
테이블스페이스(TABLESPACE)는 오라클에서 DB의 데이터를 저장하는 가장 큰 개념으로 생각하자. 개념이라는 의미는 실체로 존재하지 않지만, 오라클의 저장 구조를 이해하기 위한 개념적인 의미의 저장 공간을 말한다. 여러분이 하나의 테이블을 생성하였다면 생성된 테이블은 반드시 저장되어야 한다. 그렇다면, 어디에 저장될까? 정답은 테이블스페이스이다. 여러분이 테이터베이스 객체를 생성하거나 생성된 테이블에 데이터를 추가하고 정상적으로 트랜잭션을 종료하면 추가된 데이터 역시 테이블 스페이스에 저장된다.
CONN hr
SELECT default_tablespace
FROM user_users;| DEFAULT_TABLESPACE |
| USERS |
HR 계정으로 접속하여 USER_USERS 데이터 사전을 조회하면 HR 계정으로 만든 데이터베이스 객체가 어떤 테이블스페이스에 저장되는지의 정보를 얻을 수 있다. 위 결과는 USERS를 기본 테이블스페이스로 사용하고 있다. 즉 앞서 생성한 TEST_EXTENT 테이블 역시 HR 계정으로 생성하였다면 당연히 USERS 테이블스페이스에 저장해 두었다는 것이다.
CONN hr
SELECT tablespace_name
FROM user_tables
WHERE table_name = 'TEST_EXTENT';일반적으로 테이블스페이스는 생성 초기에는 한 개의 데이터 파일을 소유하고 있는데 DBA가 데이터의 양이나 그 성격에 따라서 데이터 파일을 추가할 수 있다.
하나의 데이터베이스는 반드시 한 개의 SYSTEM과 SYSAUX 테이블스페이스를 가지며, SMALLFILE TABLESPACE를 생성한다. SYSTEM 테이블스페이스는 데이터베이스 레벨에서 볼 때 논리적으로 하나의 테이블 스페이스로 구성되어 있다. 또한, DATA1.ORA와 DATA2.ORA 라는 한 개 이상의 데이터 파일로 구성되어 있음을 알 수 있다.
CREATE TABLESPACE users
DATAFILE 'DATA3.ORA'현재 여러분의 시스템에서의 테이블스페이스는 어떻게 구성되어 있을까? DBA 권한을 가진 사용자(예. SYSTEM)로 접속하여 확인해 보자.
CONN system
SELECT tablespace_name, status
FROM dba_tablespaces;| TABLESPAE_NAME | STATUS |
| SYSTEM | ONLINE |
| UNDOTBS1 | ONLINE |
| SYSAUX | ONLINE |
| TEMP | ONLINE |
| USERS | ONLINE |
| EXAMPLE | ONLINE |
데이터 사전 dba_tablespace에 tablespace_name과 status 칼럼을 조회한 결과이다. tablespace_name은 현재 DB에 존재하는 테이블스페이스의 이름을 나타낸다. status 칼럼의 ONLINE은 현재 사용 가능한, 즉 DB 객체나 데이터의 저장이 가능한 상태임을 나타낸다.
ERROR: ORA-04043 : object "SYS"."DBA_TABLESPACES" does not exist
SYS 사용자 소유의 DBA_TABLESPACE가 존재하지 않는다는 오류이다. 여러분도 알고 있듯이 DBA로 시작하는 데이터 사전은 DBA 권한을 가진 사용자만이 접근할 수 있다. 데이터베이스 생성 시 기본적으로 생성되는 SYSTEM이나 SYS 사용자가 그 대상이 된다.
SHOW USER명령으로 현재 접속 중인 사용자의 정보를 확인해보자. DBA 권한이 있는 사용자인가?
앞서 설명한 테이블 스페이스와 데이터 파일과의 관계를 나타내기 위해서는 데이터 사전 dba_data_files를 참고하자.
CONN system
SELECT TABLESPACE_name, file_name, bytes
FROM dba_data_files;| TABLESPACE_NAME | FILE_NAME | BYTES |
| USERS | D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\USERS01.DBF | 5242880 |
| SYSAUX | D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\SYSAUX01.DBF | 220200960 |
| UNDOTBS1 | D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\UNDOTBS01.DBF | 26214400 |
| SYSTEM | D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\SYSTEM01.DBF | 461373440 |
| EXAMPLE | D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\EXAMPLE01.DBF | 157286400 |
데이터 사전 dba_data_file에 tablespace_name과 file_name 그리고 bytes 칼럼을 조회한 결과이다. file_name은 각 테이블스페이스를 구성하는 데이터 파일의 물리적 위치와 파일 이름의 정보를 제공한다. Bytes는 각 데이터 파일의 크기를 나타낸다. 예를 들어 users라는 테이블 스페이스는 user01.dbf라는 하나의 데이터 파일로 이루어지며, 파일의 크기가 5,242,880Bytes임을 나타내고 있다. 참고로 오라클은 최대 8Exabytes 크기의 BIGFILE TABLESPACE 생성을 지원한다.
현재 사용 중인 테이블스페이스는 향후 저장하는 데이터의 양의 증가로 말미암아 테이블스페이스의 저장 공간이 부족할 경우가 있다. 이 경우 DBA는 데이터 파일을 추가하여 테이블스페이스의 전체 저장 영역을 학장하여 사용할 수 있다.
ALTER TABLESPACE SYSTEM ADD DATAFILE 'DATA2.ORA'
ALTER TABLESPACE SYSTEM ADD DATAFILE 'DATA3.ORA'데이터 파일의 크기를 증가시켜 테이블스페이스의 크기를 늘리는 경우
ALTER DATABASE
DATAFILE 'DATA3.ORA' AUTOEXTEND ON NEXT 20M MAXSIZE 1000M
하나의 데이터베이스에는 하나 이상의 테이블스페이스를 가진다. STSTEM, SYSAUX 테이블 스페이스는 데이터베이스가 생성될 때 반드시 존재한다. 데이터베이스 운영에 필수적인 정보들을 가지고 있기 떄문이다.
하나의 테이블스페이스는 여러 세그먼트들로 구성이 된다. 112Kbytes 크기의 Segment 내에는 28Kbytes와 84Kbytes 크기의 Extent가 존재한다. 그리고 이들 Extent에는 2Kbytes 크기의 여러 블록이 존재한다. Block은 데이터를 저장하는 최소 단위이다. 이 Block에 오라클은 데이터베이스 객체와 데이터를 저장한다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
물리적 데이터베이스 구조(Physical Database Structure)
오라클의 경우 데이터베이스 생성 시 미리 일정한 크기만큼의 파일을 생성해 두고 이 파일의 크기만큼 데이터를 저장하는 방법을 사용한다.
데이터 파일(Data File)
데이터 파일이란 테이블, 인덱스 등의 데이터베이스 객체를 물리적으로 저장하는 파일을 말한다. 테이블에 하나의 데이터를 추가하고, 정상적으로 트랜잭션을 종료(COMMIT)하면 추가된 데이터는 최종적으로 데이터 파일에 저장된다.
오라클에서 데이터 파일은 테이블스페이스와 함께 생각해 보아야 한다. 테이블스페이스는 생성시 하나 또는 그 이상의 데이터 파일로 구성된다. 그리고 하나의 데이터 파일은 반드시 하나의 테이블 스페이스와 관계를 맺고 있다.
테이블 데이터베이스 객체인 테이블이 두 개의 파일에 걸쳐서 표현되었는데, 이는 데이터 파일에 저장되는 데이터베이스 객체가 물리적인 데이터 파일의 영역이 아닌 테이블스페이스의 논리적인 저장영역 형태로 영역을 할당받는다는 것을 나타내고 있다. 이는 오라클 DB가 데이터 저장 및 관리를 논리적인 테이블스페이스로 하고 있다는 것을 말한다.
컨트롤 파일(Control File)
컨트롤 파일(Control File)은 DB의 물리적인 구조를 저장해 두는 파일이다. 컨트롤 파일은 오라클 인스턴스와 DB 데이터 파일, 온라인 리두 로그 파일을 연결하는 역활을 한다.
컨트롤 파일은 바이너리 파일이므로 직접 열어서 확인할 수는 없다.
CONN system
ALTER DATABASE BACKUP CONTROL TO TRACE;
SHOW PARAMETER user_dump_dest| NAME | TYPE | VALUE |
| user_dump_dest | string | D:\ORACLE\PRODUCT\10.1.0\ADMIN\ORCL\UDUMP |
파라미터 파일을 열어 USER_DUMP_DEST의 실제 경로를 확인해보자. 이 경로에서 현재 운영중인 컨트롤 파일의 정보를 얻을 수 있다. 위 경로에 수정한 날짜가 가장 최근인 .TRC파일을 열어보자. 컨트롤 파일이 생성되면서 아래와 같은 내용을 저장한다.
Dump file d:\oracle\product\10.1.0\admin\orcl\udump\orcl_ora_2896.trc
Wed Jun 16 16:10:53 2004
.
.
-- ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE PERFORMANCE
STARTUP NOMOUNT
CREATE CONTROLFILE REUSE DATABASE "ORCL" NORESETLOGS NOARCHIVELOG
MAXLOGFILES 16 -- 최대 로그 파일의 수
MAXLOGMEMBERS 3 -- 최대 로그 파일의 멤버 수
MAXDATAFILES 100 -- 최대 데이터 파일의 수
MAXINSTANCES 8 -- 최대 Instance의 수
MAXLOGHISTORY 454
LOGFILE -- 로그 파일의 경로와 이름 그리고 크기
GROUP 1 'D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\REDO01.LOG' SIZE 10M,
GROUP 2 'D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\REDO02.LOG' SIZE 10M,
GROUP 3 'D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\REDO03.LOG' SIZE 10M
-- STANDBY LOGFILE
DATAFILE -- 데이터 파일의 경로와 이름 그리고 크기
'D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\SYSTEM01.DBF',
'D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\UNDOTBS01.DBF',
'D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\SYSAUX01.DBF',
'D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\USERS01.DBF',
'D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\EXAMPLE01.DBF'
CHARACTER SET KO16MSWIN949 -- 데이터베이스 문자 셋
;컨트롤 파일은 DB의 물리적인 구조 정보를 가지고 있어서 DB가 시작될 떄나 DB 복구할 떄 항상 참조되는 파일이다.
온라인 리두 로그 파일 처럼 컨트롤 파일 역시 대단히 중요한 파일이므로 물리적으로 나누어진 2개 이상의 디스크에 2개 이상의 컨트롤 파일을 사용하여야 디스크 장애 등의 문제가 발생할 떄 DB를 복구할 수 있다. 리두 로그의 복합 구조(Multiplexed)와 다른 점은 로그 시퀀스 번호에 따라 파일마다 다른 정보를 저장하는 것이 아니라, 항상 데이터베이스 구조 정보를 똑같이 복사해 두고 있다는 것이다.
컨트롤 파일의 설정은 아래와 같이 확인할 수 있다.
CONN system
SHOW PARAMETER control_files| NAME | TYPE | VALUE |
| control_files | string | D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\CONTROL01.CTL, D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\CONTROL02.CTL, D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\CONTROL03.CTL |
아래와 같이 데이터사전 v$controlfile 를 질의하여도 동일한 결과를 얻을 수 있다.
CONN system
SELECT name
FROM v$controlfile;
리두 로그 파일(Redo Log File)
이미 독자분들과 함께 DB의 모든 변경 정보를 원본과 함께 저장하는 SGA 내의 리두 로그 버퍼에 대해 알아보았다. 바로 이 정보를 메모리 영역이 아닌 물리적인 파일 형태로 오라클 Db가 가지고 있는 것이 온라인 리두 로그 파일(On-Line Redo Log File)이다.
여러분이 COMMIT 명령어를 실행하면 리두 로그 버퍼에 가지고 있던 변경 값과 원본 값을 LGWR(LogWrier) 프로세스가 바로 리두 로그 파일에 저장한다. 데이터베이스가 시작되면, 테이블을 생성/변경/삭제하거나 데이터를 추가/수정/삭제하는 데이터베이스 변경 사항이 발생 시 변경 값과 원본 값을 리두 로그 버퍼에 저장하게 된다. 리두 로그 파일은 데이터베이스를 복구할 때 꼭 필요한 파일이므로, 디스크와 그룹 형태로 미러링(mirroring)한 Multiplexed Online Redo Log 형태로 구성하여 운영해야 한다.
LGWR(LogWriter) 프로세스가 SGA내의 리두 로그 버퍼의 값을 리두 로그 파일에 저장할 때 Group#1 -> Group#2 -> Group#3 -> Group#1 순서로 순환하면서 저장한다. Group#1 에서 Group #2로의 변경을 로그 스위칭(Log Switching)이라 하며, 로그 스위칭이 발생하면 로그 시퀀스가 증가한다.
물리적으로 다른 2개의 디스크 상에 Member A, B로 리두 로그 파일이 설정되어있다. 이 떄 Member A와 Member B는 동일한 리두 로그의 정보를 가지면서 서로 다른 물리적 디스크에 존재한다. 따라서 한쪽의 디스크를 사용하지 못하는 경우가 발생하더라도 동일한 내용을 물리적으로 다른 디스크에서 가지고 있기 떄문에 복구될 수 있다.
참고로 사용자가 DB를 아카이브 모드로 설정했다면 로그 스위칭될 때마다 아카이브 프로세스는 로그 시퀀스 번호대로 리두 로그를 복사하여 설정된 저장소에 저장하게 된다.
SELECT group#, members, bytes, archived, status
FROM v$log;| GROUP# | MEMBERS | BYTES | ARCHIVED | STATUS |
| 1 | 1 | 10485760 | NO | INACTIVE |
| 2 | 1 | 10485760 | NO | INACTIVE |
| 3 | 1 | 10485760 | NO | CURRENT |
v$log의 조회 결과이다. 여러분의 PC에 기본으로 설치된 Oracle에서 운영되는 로그 파일의 정보이다. 하나의 member로 구성되므로 단일 디스크에 존재하고 별도의 미러링을 하지 않는다. group#은 3개로 구성되어 순환되면서 기록됨을 보여주고 있다. 각 로그 파일의 크기는 모두 100MBytes 정도의 크기이다.
또한, 로그 파일들 모두 archiving이 되지 않고 있으며, status는 LGWR(LogWriter) 프로세스가 SGA 내의 리두 로그 버퍼의 값을 리두 로그 파일에 저장할 떄, 현재 current로 설정된 group#3에 기록하고 있음을 나타내고 있다.
SELECT group#, type, member
FROM v$logfile;| GROUP# | TYPE | MEMBER |
| 3 | ONLINE | D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\REDO03.LOG |
| 2 | ONLINE | D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\REDO02.LOG |
| 1 | ONLINE | D:\ORACLE\PRODUCT\10.1.0\ORADATA\ORCL\REDO01.LOG |
v$logfile의 조회 결과이다. v$logfile은 로그 파일의 물리적인 위치 정보를 제공해 준다. member 칼럼의 내용을 보면 각 리두 로그 파일이 어떤 위치에 현재 저장되고 있는지 보여주고 있다. Type은 현재 하나의 member로 구성된 3개의 리두 로그 파일 모두가 사용이 가능한 상태(online 상태)임을 나타낸다.
아카이브 로그 파일(Archive Log File)
아카이브(Archive)는 사전적으로 '저장하다'라는 의미이다. 아카이브 로그 파일(Archive Log File)은 말 그대로 온라인 리두 로그 파일이 로그 시퀀스 번호대로 저장되어 있는 것을 말한다. 즉 앞서 설명한 온라인 리두 로그 파일의 저장 내용을 모두 가지고 있는 파일이라고 생각하면 된다.
온라인 리두 로그 파일이 순환 형태로 데이터를 저장하기 떄문에 여러분이 DB에 아카이브 설정을 하지 않았다면, 계속해서 지정된 온라인 리두 로그 파일에 데이터를 저장하므로 파일에 덮어 쓰게(Overwrite)되는 일이 발생한다. 이 경우 데이터베이스의 정상적인 복구가 불가능하게 된다. 현재 시스템에서 아카이브 로그 파일의 설정 상태는 v$log 데이터 사전을 통해 얻을 수 있다.
아카이브 로그 파일은 DB가 아카이브 모드일 때 생성되는 파일이다. 아카이브 로그 프로세스는 온라인 리두 로그 파일 중 덮어 쓰게 될 로그 시퀀스를 가진 파일의 이미지를 복사하여, 로그 시퀀스 번호대로 리두 로그 파일에 저장하게 된다. 이렇게 저장된 파일들은 향후 DB를 특정 시점에 부분적인 복구를 하거나 Oracle Log Miner를 이용하여 데이터를 복구할떄 유용하게 사용된다.
파라미터 파일(Parameter File)
Parameter File은 Oracle Instance의 SGA 크기 등 해당 오라클 인스턴스의 기능과 성격을 기록해 놓은 파일이다. 즉 파라미터 파일을 통해 오라클 인스턴스가 어떻게 운영되는지 특성을 알게 된다.
파라미터 파일은 오라클 인스턴스를 시작할 때 필요한 파일이다. 오라클 인스턴스를 시작할때 파라미터 파일을 읽어 오라클이 필요로 하는 자원을 얻게 된다. 오라클 DB는 사용자가 DB를 시작하려 할 때 'SYSTEM_DRIVE:\Oracle\product\10.2.0\admin\oracle_sid\pfile\init.ora' 에 기술된 파라미터들에 따라 인스턴스의 구조를 생성하게 된다. 반면 Server Parameter File(서버 파라미터 파일: 이하 SPFile)은 오라클 DB 서버에서 관리하는 작은 크기의 이진(Binary) 파일로, 서버에 의해 변경된 오라클 인스턴스 파라미터 값을 지속적으로 저장하고 관리한다.
만일 여러분의 시스템에 Sever Parameter File이 존재한다면 Parameter File 내의 값을 변경하여도 제대로 반영되지 않는 난감한 경우를 맞을 수도 있다. 왜냐하면, 오라클 인스턴스는 항상 SPFile을 우선시 하기 때문이며, SPFile에 기록된 정보를 바탕으로 오라클 인스턴스를 설정하기 때문이다.
아래는 SPFIle의 일부 설정 사항이다.
-- CONTROL FILE의 물리적인 위치와 이름을 나타낸다. control_files를 구성하는 요소들은
-- 쉽게 볼 수 있도록 다른 줄로 구분하였다.
.
.
*.control_files = 'D:\oracle\product\10.1.0\oradata\orcl\control01.ctl',
'D:\oracle\product\10.1.0\oradata\orcl\control02.ctl',
'D:\oracle\product\10.1.0\oradata\orcl\control03.ctl'
.
.
-- BLOCK 하나의 크기를 나타낸다. 단위는 Bytes 이다.
*.db_block_size = 8192
-- Oracle Server가 동시에 읽을 수 있는 BLOCK의 수를 나타낸다.
*.db_file_multiblock_read_count = 16
-- DATABASE의 이름을 나타낸다.
*.db_name = 'orcl'
.
.
-- SGA 영역의 크기를 나타낸다.
*.shared_pool_size = 83886080
.
.Alert와 Trace 파일
Alert와 Trace 파일은 Oracle의 이상 반응에 대한 일종의 보고서와 같은 역활을 한다.
오라클 DB 서버 시스템은 운영 중에 백그라운드 프로스세와 DB 서버가 시스템 내부적인 에러나 시스템 변경 상황, 그리고 사용자가 DB를 운용할 때의 에러 등을 감지하여 Trace File을 생성하며, Alert File에 기록하게 된다.
DB의 Alert 파일에는 다음과 같은 에러 발생이나 명령 수행을 시간순으로 기록한다.
- Internal errors(ORA-600)
- block corruption errors(ORA-1578)
- deadlock(교착 상태) errors(ORA-60)
- Administrative operations(DDL)
- Server Manager statement(STARTUP, SHUTDOWN, ARCHIVE LOG, REVOVER)
- 데이터베이스를 시작할 때 읽은 파라미터 값(parameter value)
Alert File과 Trace File의 경로와 위치는 파라미터 파일을 통해 아래와 같이 얻을 수 있다.
CONN system
SHOW PARAMETER background_dump_dest| NAME | TYPE | VALUE |
| background_dump_dest | string | D:\ORACLE\PRODUCT\10.1.0\ADMIN\ORCL\BDUMP |
Alert File의 내용을 살펴보자
-- 데이터베이스가 시작된 상태를 나타내고 있다.
Tue Oct 15 10:55:04 2022
Starting oracle instance (normal)
LICENSE_MAX_SESSION = 0
LICENSE_SESSIONS_WARNING = 0
Starting up ORACLE RDBMS Version: 10.1.0.2.0.
.
.
alter database mount exclusive
Tue Oct 15 10:55:19 2022
.
.
alter database open
.
.
-- 데이터베이스의 구조에 접근하는 명령문을 수행하였을 때 그 로그를 기록한다.
ALTER DATABASE BACKUP CONTROLFILE TO TRACE
Wed Oct 16 16:10:55 2022
Completed: ALTER DATABASE BACKUP CONTROLFILE TO TRACEbackground_dump_dest
Alert File과 백그라운드 프로세스가 감지한 시스템 변경사항이나 내부 에러를 기록하는 파일들의 물리적인 위치를 나타낸다.
core_dump_dest
데이터베이스 시스템에서 사용자가 실행한 어떤 특정 작업 중 시스템에 손상을 일으킬 특정 작업에 대해 Trace File을 생성하는 물리적인 위치이다.
user_dump_dest
사용자가 데이터베이스를 운영할 때 에러 등을 감지하여 생성되는 파일들의 물리적인 위치이다. 교착 상태가 발생했을 때 생성된 Trace File이 이곳에 저장되어 데이터베이스 관리자에게 교착 상태의 정보를 제공한다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------Deadlock(교착 상태)는 어떤 상황에서 발생할 수 있을까?
둘 이상의 Thread 간에 일부 리소스에 대한 순환 종속 관계가 있는 경우 교착 상태가 발생한다.
교착 상태는 단순한 관계형 데이터베이스 관리 시스템이 아니라, 여러 Thread가 있는 시스템에서 발생할 수 있다. 멀티 Thread 시스템의 Thread는 하나 이상의 리소스(예. 잠금)를 얻을 수 있다. 원하는 리소시를 현재 다른 Thread가 소유하고 있으면 대상 리소스가 해제될 때까지 첫번쨰 Thread를 기다려야 할 수 있다. 이 떄 대기 중인 Thread는 리소스를 소유한 Thread에 대해 해당 리소스에 대한 종속 관계가 있다고 한다.
소유한 Thead에서 현재 대기 중인 Thread가 소유한 다른 리소스를 원하는 경우에는 교착 상태가 발생한다. 두 Thread 모두 트랜잭션을 COMMIT하거나 ROLLBACK할 떄까지 소유한 리소스를 해제할 수 없고, 다른 트랜잭션이 소유한 리소스를 대기하고 있으므로 트랜잭션을 COMMIT하거나 ROLBACK할 수 없다.
예를 들어, 트랜잭션 1을 실행하는 Thread T1에는 Employees 테이블에 대한 단독 잠금이 있고, 트랜잭션 2를 실행하는 Thread T2는 Departments 테이블에 대한 단독 잠금을 얻은 다음 Employees 테이블을 잠그려고 한다. 트랜잭션1이 Employees 테이블에 대해 잠금을 소유하고 있으므로, 트랜잭션2는 잠금을 얻을 수 없다. 트랜잭션 2는 차단되고 트랜잭션 1을 기다린다. 트랜잭션 1은 Departments 테이블에서 잠금을 얻으려 하지만, 트랜잭션 2가 잠궈 놓았으므로 얻을 수 없다. 트랜잭션은 COMMIT하거나 ROLLBACK할 떄까찌 잠금을 해체할 수 없으며 다른 트랜잭션이 소유한 잠금이 있어야 계속 진행할 수 있으므로 COMMIT하거나 ROLLBACK할 수도 없다.
--테이블 LOCK정보 확인
SELECT VO.SESSION_ID, DO.OBJECT_NAME, DO.OWNER, DO.OBJECT_TYPE, DO.OWNER, VO.XIDUSN, VO.LOCKED_MODE
FROM V$LOCKED_OBJECT VO, DBA_OBJECTS DO
WHERE VO.OBJECT_ID = DO.OBJECT_ID
--LOCK걸린 테이블의 SID, SERIAL을 확인한다
SELECT A.SID
,A.SERIAL#
FROM V$SESSION A
,V$LOCK B
,DBA_OBJECTS C
WHERE A.SID = B.SID
AND B.ID1 = C.OBJECT_ID
AND B.TYPE = 'TM'
AND C.OBJECT_NAME = 'PRD_PROCESS_QC_RESULT1'; --락걸린 테이블명
-- SESSION을 KILL한다,
ALTER SYSTEM KILL SESSION '113, 2468' --SID, SERIAL
'DB > Oracle' 카테고리의 다른 글
| [Oracle] Chapter 2. 오라클의 여러 프로세스 (0) | 2022.10.10 |
|---|---|
| [Oracle] Chapter 1. I/O와 디스크의 관계 (0) | 2022.10.09 |
| [Oracle] Oracle 응용 예제(OE) with XML (1) | 2022.09.26 |
| [ORACLE] DB dump 백업 및 복구 (export / emport ) & Linux 백업(Backup) 관련 tar, cpio, dump, restore, dd 명령어 (2) | 2022.09.22 |
| [Oracle] Oracle 응용 예제(OE) (0) | 2022.09.22 |

