1. ZetaData 소개
1.1. ZetaData의 배경
1.1.1. Tibero Active Cluster(TAC)
최초의 DB에서 어떤 내부조건과 어떤 제약조건에 의해서 ZetaData 구조를 가지게 되었는지 설명하도록 하겠습니다. 가장 기본적인 구조는 티베로 Server가 Single Instance로 떠서 자신의 Local Disk에 I/O를 수행합니다. 여기에서 높은 가용성을 가질 수 있도록 한 모델이 TSC(Tibero Standby Cluster)인데요, Active Server와 Standby Server가 존재합니다. Active Server에는 부하가 들어갈 수 있지만, Standby Server에는 부하가 들어가지 않고, 조회만 가능합니다. Standby Server는 Active Server의 redo log를 가지고 와서 마치 부하가 들어온 것처럼 논리적인 복제를 합니다. 2개의 DB가 처음부터 동일하게 시작하여, Standby Server가 redo log를 가지고 와서 그대로 복제했기 때 문에, Active Server에 문제가 발생하면 Standby Server가 Active Server의 역할을 대신 수행 가능하게 됩니다. 그래서 높은 가용성의 장점을 가집니다. 그래도 결국 Standby Server도 하나의 Server입니다. Standby Server의 자원(Resource)이 아깝기에 컴퓨팅 능력의 Scale out이 가능하며, 높은 가용성의 장점 을 가진 TAC(Tibero Active Cluster) 모델이 나오게 되었습니다. TAC는 Standby Server가 없고, 모든 DB가 Active Server로 존재하기 때문에, TAC 역시 높은 가용성의 장점을 가집니 다. 이전의 모델들과 제일 큰 차이점은 Shared Disk를 가진다는 점입니다. 이전의 모델들이 자신의 Local Disk에 I/O 했다면, TAC 모델에서는 모든 Active Server들이 SAN Switch를 이용해서 Shared Disk에 I/O하게 됩니다. 이는 모든 DB가 Active Server이기 위해서는 모두 같은 data를 바라봐야 하기 때문입니다.

1.1.2. Tibero Active Storage(TAS)
Tibero의 구조상 직접 Raw Device에 물려야 합 니다. Tibero는 공간관리능력이 없어서 Mirroring, Rebalance, Striping 같은 기능을 제공하지 않으 며, Disk 한 장을 하나의 파일처럼 사용해야 합 니다. 따라서 Offset의 표현 한계로 인해 Block size를 32Kb로 설정 시 최대 128Gb까지 밖에 사용하지 못합니다. 이런 점을 보완하기 위해 Volume Managing 기능을 가진 TAS가 나오게 됩니다.

TAS는 Striping, Mirroring 등의 기능을 제공해주며, 각각의 Disk들을 논리적으로 나누어서 관리하게 됩니다. Tibero Instance가 I/O를 수행하기에 하기에 앞서 TAS에게 어디 에 I/O를 수행하는지 묻고, 그 곳에서 I/O를 수행합니다. TAS가 추가 된다고 해서 I/O의 기본 구조가 기존의 구조와 달라지는 것은 없습니다. DB가 Disk에 I/O를 수행 한다라는 기존의 DB구조는 변하지 않는다는 것 입니다. 실제 I/O는 Striping, Mirroring 기능에 의해 잘게 나누어 져 관리 됩니다. 그러면 이렇게 잘게 나누어진 파일들을 어디에 저장하 는가 하는 위치정보인 Extent Map을 관리 하는 곳이 TAS의 Instance입니다. TAS는 Mirroring, Striping 기능 이외에도, 장애복구와 같은 기능도 제공해줍니다. (뒤에 별도 설명)

1.1.3. SAN의 한계
이전까지의 DB 모델들은 OLTP에 초점이 맞추어져 있 었습니다. 그래서 이런 모델들의 평가지표는 TPC-C와 같이 초당 몇 트랜잭션을 처리하느냐가 됩니다. 그러나 ZetaData는 OLTP에 초점이 맞춰져 있는 것이 아니라, OLAP에 초점이 맞추어져 있습니다. 때문에 대용량 Read/Write가 아니라, 그냥 단순히 소용량 OLTP 성 자료만 처리한다면, ZetaData 모델은 적합하지 않습니다. 적합하지 않은 이유는 ZetaData 모델을 대략적으로 설명 드린 후에 다시 자세히 설명드리겠습니다. 대용량 Read/Write 즉, 대표적으로 대용량 Loading과 대용량 Full scan 등과 같이 대용량 데이터를 처리하고 싶다는 고객의 요청이 들어왔을 때, 적합한 모델이 ZetaData입니다.

기존의 DB 구조에 대용량 데이터를 그대로 넣게 되면 2가지 큰 문제가 발생합니다. 바로 확장성과 Bottleneck입니 다. 기존의 SAN Switch는 disk를 꼽기만 하면 쉽게 Scale up이 가능합니다. 하지만 일정 이상의 Scale up 이후로는, 높은 비용이 발생하며, 확장성에 문제가 생겨서 외부에 데이터를 백업 해놓거나, 지워야 합니다. 또한 SAN Switch에 대용량 데이터 요청이 몰리게 되어 Bottleneck 현상이 생기게 됩니다
1.2. Storage Server(SSVR) & Infiniband
이런 2가지 문제를 해결한 모델이 바로 ZetaData 입니다. 확장성은 Storage Server를 둠으로써, Bottleneck은 InfiniBand를 둠으로써 해결합니다. 확장성을 위해 기존과 같이 SAN Switch를 물리게 되는 것이 아니라, Storage Server를 둡니다. 여러 장의 자신의 Local Disk를 가진 Server에 Storage 소프트웨어를 설치한 것을 Storage Server라 부릅 니다. Storage Server들은 각각 독립된 형태이기에, 어떤 Storage가 추가되거나 없어진다고 해서, 서로에게 아무런 영향을 주지 않습니다. 따라서 용량이 더 필요하다면 Storage Server Node를 추가하거나 기존의 Storage Server에 disk를 추가하는 것으로 쉽게 확장성의 문제를 해결 할 수 있습니다. Bottleneck의 문제는 기존보다 대역폭이 넓은 56Gbps 이상의 Infiniband를 씀으로써, 어느 정도 문제를 해결합니다. Infiniband는 Storage Server와 DB Server 간 통신을 위해 쓰는 것이기 때문에 Infiniband 대신 TCP를 사용해도 되지 만, TCP 사용시 성능의 저하가 발생합니다.

하지만 2가지 문제점을 해결한 구조인 ZetaData는 앞서 말씀드린 것처럼 OLTP에서는 손해가 발생합니다. DB Server 가 Infiniband를 통해서 Storage Server에 I/O를 요청하고, Storage Server는 이 요청을 받아 자신의 Local Disk에 I/O를 하고, 다시 I/O 완료되었다는 reply를 DB Server에게 되돌려주는 형태로 I/O 수행하기 때문에 응답시간은 더 길어질 수 밖에 없습니다. 따라서 기존의 구조처럼 직접 SAN Switch를 물려서 바로 Disk에 접근한 후 I/O를 수행하는 것이 Response time 측면에서는 더 좋기 때문에, OLTP성 query가 대부분을 이룬다면 ZetaData는 적합하지 않습니다. OLTP에 대한 손해는 뒤에서 Flash cache를 설명해 드리면서 느려진 OLTP를 어떻게 조금이나마 보완하였는지 설명 하겠습니다.
1.3. Function Offloading
SAN Switch보다 10배 정도 대역폭인 큰 Infiniband를 이용함으로써 Bottleneck을 줄였다고 설명 드렸습니다. 하지만 방대한 데이터를 부어 넣게 되면 여전히 Bottleneck의 문제는 남아있게 됩니다. 이렇게 남아있는 Bottleneck 문제를 해결하기 위해 추가한 기능이 Function Offloading 기능입니다. Function Offloading의 목적은 DB Server에 전송하는 데이터 양을 감소시키는 것 입니다.

Function Offloading 기능을 끄게 되면, 위쪽 그림에서 빨간 부분의 데이터를 읽고 싶다고 하더라도 Infiniband를 통해 전체 데이터를 전송합니다. 반면에 Function Offloading 기능을 켰을 때는, 그림처럼 필요한 부분을 필터링하여 전체가 아닌 일부만 DB Server에 보내게 됩니다. 즉, Function Offloading 기능은 전송량을 줄임으로써 Bottleneck 발생을 줄이는 것입니다.
데이터 이동량이 감소가 되었기 때문에 DB 대기시간 감소로 인한 대용량 Data 처리 시간 감소, Data 처리 과정 분산에 따른 CPU 사용량 분산과 같은 부수적인 장점도 함께 따라오게 됩니다.
이런 기능이 가능한 이유는 SAN Switch같이 disk를 Device에 물리는 구조가 아니라, CPU나 메모리를 가진 Server를 사용했기 때문에 가능한 구조입니다. 하지만 이렇게 단순히 Row, Column 필터링에만 Server 자원을 사용하기에는 CPU나 메모리 자원이 아깝습니다.
1.4. Storage Data Map
Function offloading 기능은 전송량을 줄일 뿐 Disk I/O는 필요한 곳만이 아니라 전체 테이블에 대해 수행하게 됩니 다. 따라서 앞서 설명한 것처럼 Server의 자원이 아까우니, Disk I/O를 줄여보자는 것이 Storage Data Map입니다. Storage Data Map은 불필요한 I/O 수행을 줄이는 것이 목적인데, 메모리상의 테이블을 잘라서 사용자가 요청한 column에 대해서 Min, Max 값을 가지고 있다가 비슷한 query로 다시 I/O 요청이 왔을 때, 필요한 부분만 Disk I/O를 수행하여 전달해주는 방식입니다.

구체적인 기능을 설명해보면 하나의 큰 테이블을 그림과 같이 특정 크기로 나누어서 관리합니다. 위에 예시에서 처 럼 C3 column에 데이터 I/O 요청이 들어오면, C3 column에 대해 구간별로 Min 값과 Max 값을 메모리에 저장하게 됩니다. 이후에 비슷한 query의 요청이 들어오게 되면, 먼저 Min, Max 값을 확인하고 I/O를 수행할지 건너 뛸지를 결정합니다. 위의 예시처럼 where절 조건이 ‘C3 column의 값이 7보다 큰 값을 가지고 와라’면, Min, Max 값을 확인 하여 구간 2에 대해서는 읽을 필요가 없는 것을 판단하고 Disk I/O를 수행하지 않습니다. Storage Data Map은 불필요한 Disk I/O를 줄이는 것이고, Function Offloading 기능은 Network를 통해 보내는 전송량을 줄이는 것이기 때문에, Storage Data Map 기능은 Function Offloading 기능보다 먼저 수행됩니다.
다시 한번 정리하면, Storage Data Map은 읽기 전에 미리 읽을지 말지를 판단하여 불필요한 Disk I/O가 감소하는 장점을, Function Offloading은 읽어온 데이터를 Row, Column Filter로 전송량을 줄이는 장점을 가진 기능입니다.
1.5. Flash Cache
앞서 설명드린 느려진 OLTP를 조금이나마 보완해주는 것이 Flash Cache 입 니다. 이것은 Disk보다 빠른 Flash Cache를 Cache로써 활용하는 것입니다.

자주 사용되는 Hot Data를 Cache로써 사용하고, Write-back 함수를 적용하여 Flash Cache에 접근해서 Read/Write를 수행함으로써 느려진 OLTP의 속도를 향상한 것입니다.
1.6. I/O Resource Manager(IORM)
결국엔 OLTP의 요구조건도 어느 정도 만족하고, 대용량의 OLAP를 처 리하면서 다양한 query들을 수행할 수 있게 됩니다. 때문에 그림과 같이 다양한 query가 들어올 수 있게 됩니다. 이 때, 중요한 업무가 장기 수행되는 분석 업무에 의해 부정적인 영향 없이 필요한 성능을 보장해주고자 하는 기능이 IORM(I/O Resource Manager)입니다.

이 기능은 사용자가 정한 가중치에 따라 처리하여 사용자에게 어느 정도 성능을 보장해주는 기능입니다.
1.7. Tibero Columnar Compression(TCC)
TCC(Tibero Columnar Compression)기능은 대용량을 처리하면서 압축이 필요하게 되어 나온 기능입니다.

TCC는 ZetaData뿐만 아니라 티베로에서도 사용할 수 있는 압축 방식입니다. 기존에 Dictionary 방식을 이용하여 압축했다면, TCC는 column을 모아서 압축합니다. Dictionary 형태에서 압축하는 것보다 column 형태로 하는 것이 비슷한 데이터도 많아 압축 효율이 높습니다.
그래프에서처럼 압축 효율이 훨씬 높아졌음을 확인하실 수 있습니다. 사용자가 Query Low, Query High, Archive Low, Archive High 와 같이 압축 옵션을 줄 수 있습니다. 옵션에 따라 압축 후의 용량과 시간이 달라집니다. 압축 효율이 더 높을수록 시간은 더 걸리게 됩니다.
1.8. Fault Recovery(장애복구)

TAS는 Disk나 Storage Server에 장애가 발생하면 자동으로 감지합니다. 실패를 감지하고, 다시 복구되면 Synchronizing 과정을 거치게 됩니다. 장애가 발생하면 이후의 부하들은 stale check라고 해서 계속해서 checking을 해놓게 됩니다. 다시 Disk가 복구되었을 때, checking 해놓았던 것을 적용합니다. 이런 과정이 Synchronizing입니다. TAS를 넣게 됨으로써 문제를 자동으로 감지해 I/O에 대한 Fail-over를 수행함으로써 장애복구를 하는 것입니다.
1.9. ZetaData Architecture
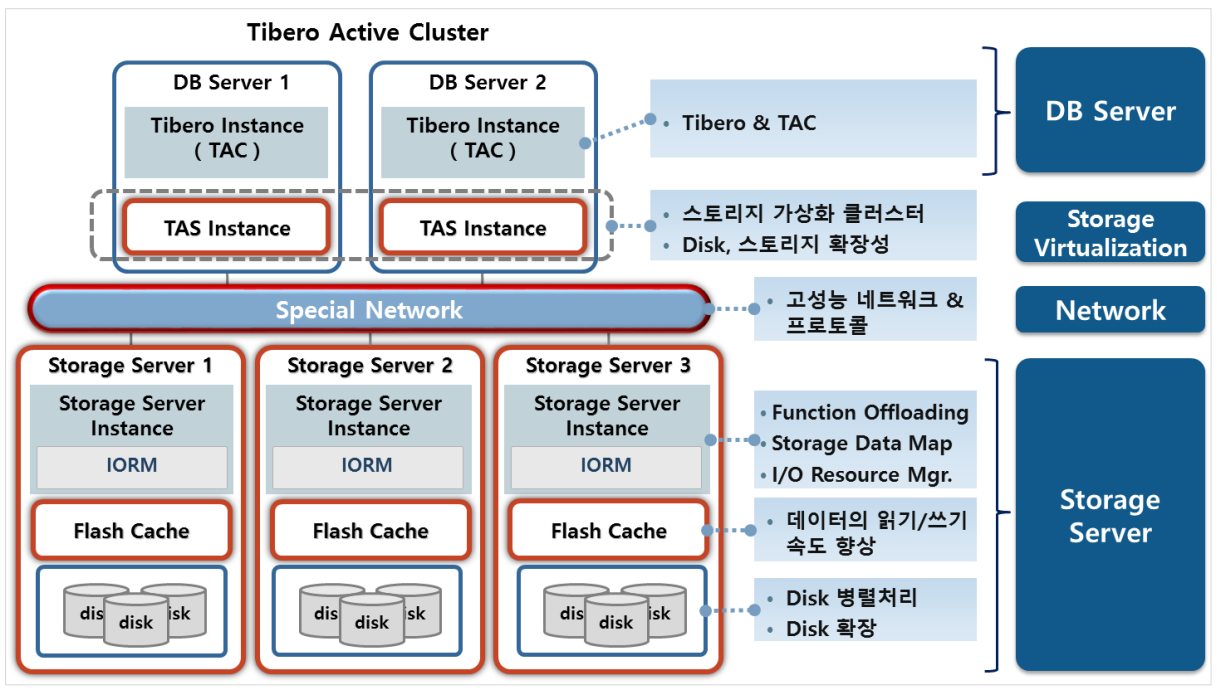
Volume Managing을 위해서 TAS가 들어간 것이고, Bottleneck 해결을 위해서 Special Network인 Infiniband가 들어갔 습니다. 또, 많은 양의 데이터가 들어오면 한계점 갖는 것을 보완하기 위해 Function Offloading 기능이 들어간 것이 고, 느려지는 OLTP를 보완하기 위해 Flash Cache가 들어간 것입니다. 이것이 ZetaData의 전체적인 구조입니다.
2. ZetaData의 설치
2.1. 하드웨어 구성

하드웨어 구성에서 중점적으로 보아야 할 것은 Processors, Memory, Local Disk입니다. Storage Server와 DB Server의 Spec은 다릅니다. DB Server는 query에 대한 연산이 많이 일어나기 때문에 많은 코어와 많은 Memory를 가져야 하고, Storage Server는 I/O 수행이 주목적이므로 Flash와 Local Disk가 더 많이 필요합니다.
예를 들어, DB Server의 Local Disk 600Gb 4개는 대부분 OS File system으로 사용하게 됩니다. 보통은 600Gb 1개 또는 2개를 OS Mirroring으로 사용하고, 나머지는 사용자가 마운트하여 필요할 경우 쓸 수 있도록 합니다. Storage Server 는 Local Disk 전부를 저장 공간으로 사용하게 됩니다.
2.2. ZetaData 설치 순서
① RAID 구성 → ② OS 설치 → ③ 커널 파라미터 설정 → ④ 계정 생성 → ⑤ udev rule 적용 → ⑥ 바이너리 설치 → ⑦ tip, dsn 파일 설정 → ⑧ SSVR Instance 생성 → ⑨ TAS Instance 생성 및 Thread 추가 → ⑩ TAS 부팅 → ⑪ TAC Instance 생성 및 Thread 추가 → ⑫ TAC Instance 부팅
2.3. RAID 구성

DB Server의 경우 600Gb 4개 중 Mirroring이 필요 하면 2개를 Mirroring으로 구성하게 되고, 그렇지 않을 때는 1개를 OS로 쓰게 되지만 Storage Server는 조금 다릅니다. 다소 복잡하여 그림과 같이 Storage Server에 4Tb Disk가 3개 있다고 가정하고 설명 드리겠습니다. RAID 기능이 없으면 OS 영역을 400Gb 잡게 되고, 나머지 영역인 3.6Tb를 Storage Disk로 구성하고, 남은 2개의 4Tb disk를 Storage Disk로 구성합니다.

만약에 RAID 구성이 필요하다면 4Tb Disk 2개를 Mirroring으로 구성합니다. 그러면 4TB Disk 2개처럼 보이게 됩니다. 이렇게 Mirroring으로 구성한 곳에 400Gb OS 영역을 할당하면, OS영역 400Gb가 Mirroring으로 구성되고, 이후에 나머지 3.6Tb 부분을 논리적으로 분리해줍니다. 분리한 부분과 남은 Disk 1개를 Storage Disk로 사용하면, 그림과 같이 3.6Tb 2개와 4Tb 1개로 Storage Disk가 구성됩니다.
2.4. 커널 파라미터 설정
Kernel.shmmax = $ free –b (mem total 값)
Kernel.shmall = Kernel.shmmax / Page Size ($ getconf PAGESIZE)
수정 후 $ sysctl -p /etc/sysctl.conf 로 변경사항 적용

커널 파라미터의 경우, shmmax에는 free –b 명령어를 이용하여 나온 값 중 메모리 Total 값을 적어주면 되고, Kernel shmall에는 shmmax를 page size로 나눈 값을 넣어 주면 됩니다. 수정 후, 변경사항을 적용하면 커널 파라미터 설정 이 완료됩니다
2.5. udev rule

$ vi gen_udev_rule.conf
$ ./gen_udv_rule.sh > etc/udev/rules.d/99-zeta.rules Run as Root
Run as Root


ZetaData 설치를 위해 udev rule을 적용해야 합니다. Device의 권한설정을 변경해주고, Symlink로 이어주는 작업을 수행합니다. 연구소에서 제공하는 gen_udev_rule을 이용하면 udev를 설정을 반자동으로 해줍니다. 이 gen_udev_rule 를 사용하는 방법에 대해 간략하게 설명하겠습니다. 먼저 gen_udev_rule.conf 파일을 열어, User의 ID와 Storage Server에 사용하고자 하는 Disk들을 순서대로 적어줍니다. 마찬가지로 Flash도 사용하고자 하는 카드를 순서대로 적 어줍니다. gen_udev_rule.conf를 수정한 후, gent_udev_rule.sh를 실행하면 자동으로 rule을 만들어 줍니다.
2.6. udev rule script


간단하게 gen_udev_rule.sh를 설명해 드리면, scsi_Id를 가져오는 것입니다. 먼저 config 파일을 읽고, 각각의 disk list 와 flash list를 가져옵니다. 이 list에서 차례대로 scsi_id를 가져와 rule을 생성해줍니다. mode라든지, owner까지 같이 넣어서 udev를 만들어 주는 것입니다. 그래서 사용자가 Zeta가 되고, 사용자의 권한설정과 사용자의 Symlink까지 연결된 것을 확인하실 수 있습니다. 즉, 이 상태까지 완료하면 Storage Server가 Local Disk를 Storage Disk로 사용할 준비가 완료된 것입니다.
2.7. 바이너리 설치
Tar 파일을 각각의 Server에 보내고, 압축 해제하면 됩니다.
2.8. tip, dsn 파일 설정

Storage Server 0, 1, 2와 DB Server 0, 1이 있다고 할 때, DB Server에는 TAS와 TAC가 뜰 것이기 때문에 tas.tip, tac.tip 파일, 클라이언트의 접속정보가 있는 tbdsn.tbr과 Storage 접속정보가 있는 ssdsn.tbr이 들어가게 됩니다. Storage Server에는 Instance를 띄우는데 필요한 ssvr.tip과 클라이언트, Storage 접속정보가 있는 tbdsn.tbr, ssdsn.tbr이 들어갑니다.

서로 크게 다른 부분은 없고, 우선 TAS 같은 경우에는 disk string이라고 해서 disk의 위치와 disk의 이름들을 적지만, ZetaData를 사용할 때는 AS_SCAN_SSVR_DISK=Y로 설정해주셔야 합니다. 해당 파라미터는 TAS가 Storage Server를 찾아가는 파라미터라고 보시면 됩니다.

TAC를 보면 기존에는 Local Disk의 위치를 적어주었다면, ZetaData 구성에서는 Disk의 Space를 만들어 사용하므로 자신이 만든 Disk Space, 예시에서는 +DS0 를 위치로 지정을 해주게 됩니다. 그리고 Storage Server, TAC, TAS가 모두 TCP로 통신한다면 SSVR_USE_TCP=Y로 켜서 TCP로 통신하도록 설정해줍니다.

Ssdsn.tbr 은 Storage Server의 IP 정보와 Port 정보를 적어주면 됩니다. Infiniband를 쓸 때는 Infiniband IP가 들어가게 되고, TCP 통신을 할 때는 TCP/IP가 들어가게 됩니다.
2.9. SSVR Instance 생성


Storage Server의 생성 스크립트인데요, Storage Disk로 자신의 Local Disk를 등록하게 되고, Storage Disk를 grid disk로 등록하게 됩니다. 여기서 grid는 create_tas.sh 일부에서 보듯이 TAS가 Storage Server의 disk를 볼 때와 같이, 외부에 서 disk를 볼 수 있도록 생성하는 것이 grid disk라고 보면 됩니다.
아래 줄은 Create Flash Cache를 추가하는 것으로 0부터 4개를 추가하겠다는 의미입니다. 지금은 해당 기능이 개선 되어 size를 기입하지 않으면 자동으로 최대 size로 들어가게 됩니다. 물론 이전처럼 size를 따로 줄 수도 있습니다.
여기서 용량 단위가 1Tb를 1024gGb로 계산한 값이기 때문에, 1Tb를 1,000Gb로 계산하는 fdisk로 조회 시 다시 1024Gb 단위로 계산해서 기입해주어야 합니다.
마지막으로 tbboot mount를 하게 되면, Storage Server Instance가 뜨게 됩니다.
2.10. TAS Instance 생성 및 Thread 추가
Create_tas 에서는 미리 지정해놓은 Storage Server IP와 Port 넘버, Size를 그대로 grid disk 순서대로 가지고 와서 보게 됩니다.


Storage Server 1, 2, 3 Instance가 각각 뜨면 DB Server TAS와 TAC를 띄워야 합니다. TAS Instance의 과정은 create_tas.sh를 실행하는 것으로 Instance가 생성됩니다. Script 파일은 DB Server 0에서 실행하면 됩니다. Disk space DS0 normal redundancy로 만드는데 이 때, normal redundancy는 2 copy를 의미합니다. normal redundancy 이외에도 external redundancy, high redundancy가 존재하는데, external redundancy는 하나의 copy, 즉 copy가 존재하지 않는 것이고, high redundancy는 3개의 copy가 존재하는 것입니다. 그리고 각각의 failgroup에, 이전에 생성했던 Storage Server의 Instance 접속 정보와 IP와 grid disk를 어떻게 추가할 것인지를 씁니다. 그림에서 보면 failgroup은 normal redundancy 2 copy를 쓰게 되는 경우, 데이터를 저장할 때 같은 copy본이 같은 failgroup에 들어가지 않게 저장됩니다. 이 말은 나중에 failgroup 하나가 장애가 발생하더라도 다른 failgroup에 copy본이 들어가 있으므로 가용성을 높일 수 있습니다. 그러므로 보통 같은 failgroup에는 같은 Storage Server에 Disk들을 넣어두게 되고, 다른 failgroup에 는 다른 Storage Server의 Disk를 넣어 두게 됩니다. 이렇게 되면, 하나의 Storage Server 전체가 장애가 발생해 내려 가게 되더라도 다른 Storage Server에 copy가 존재하기 때문에 장애 없이 계속해서 수행할 수 있게 됩니다.

이 스크립트를 첫번째 DB Server에서만 돌리게 되면, TAS가 생성되는데, 다른 TAS의 thread 추가는 alter diskspace DS0 add thread 1이라고 명시를 해놓으면 두번째 DB Server에서는 tbcm –b와 tbboot만 하면 자동적으로 Instance가 뜨게 됩니다. 만약 이 이외의 DB Server에 TAS를 더 끼우고 싶다면 add thread 2, add thread 3 이런 식으로 추가하 시고, DB Server 3과 DB Server 4에 가셔서 tbcm –b와 tbboot을 하시면 됩니다.

2.11. TAC Instance 생성 및 Thread 추가


TAC는 기존과 동일하게 구성이 됩니다. 그러나 위치는 조금씩 다릅니다. 이전에 DS0를 생성해서 여기에 log파일 등 중요 파일들을 저장하는데, Local의 위치가 아니라, 앞에서 생성한 +DS0, 즉 diskspace DS0에 생성해주겠다고 명시 하면 됩니다. 이 스크립트는 첫번째 Database Server에서만 수행하시면 됩니다. 첫번째 Database Server에서 수행한 이후, TAC 노드 추가 시, alter database enable public thread 1 이라고 해주었는데 다른 DB Server에도 마찬가지로 TAC를 띄우고 싶을 때에는 thread 2, 3, 4 추가를 해서 tbcm –b, tbboot을 실행하면 됩니다.

3. ZetaData 기능별 예시와 참고사항
3.1. Function Offloading

alter session set _storage_processing = Y; 하면 Storage Server의 프로세싱 기능을 사용하겠다는 의미입니다. Session 파라미터로 지정해서 where절 조건에 집어넣게 되면 필터링을 거쳐서 DB에 전달하게 됩니다.
Function Offloading은 Full Scan일 경우에만 효과적입니다. Index를 이용한 Scan일 경우 따로 Hint를 줘서 사용해야 하고, 전체 데이터를 버퍼 캐시에 올릴 수 없을 정도로 조회하려는 양이 많은 경우 유리합니다
3.2. Storage Data Map

이것도 이전과 차이가 크지 않습니다. Processing을 Y로 주고, where절에 값을 주게 되는데, 다른 점은 처음에 조회 하게 되면, Memory 영역에 각각 구간별로 Min, Max 값을 들고 있게 됩니다. 즉, 한 번 조회가 일어나야 Storage Data Map에 대한 기능이 작동합니다. Full Scan일 경우에 적용되고, where절 조건에 포함된 column들이 생성 대상입 니다.
한 번 올라갔을 때, 메모리에 Min, Max 값이 저장되는데 테이블이 자꾸 변하게 되면, 기존의 Min, Max 값은 사용할 수 없게 됩니다. 따라서 데이터 변경이 많은 OLTP는 Min, Max 값을 계속 저장하고 지우는 것을 반복하는 오버헤드가 발생하여 오히려 성능 저하의 원인이 됩니다. 그래서 대용량 데이터이면서 주로 Full Scan이 자주 일어날 때 사용하는 것이 유리합니다.
3.3. TCC예시

앞에 보셨던 것처럼, 압축 옵션을 Query Low, Query High, Archive Low, Archive High로 주면, 해당 옵션에 따라서 압축이 진행됩니다.
3.4. TCC참고사항
Update(또는 delete)가 거의 없는 테이블에 사용하는 것이 유리하고, Full table scan이 주로 쓰이는 테이블에 사용하 는 것이 유리합니다. 또, Projectivity가 큰 테이블에 사용하는 것이 유리한데, 관리 단위인 CU로 필요한 column들의 Block header만 보고 필요한 column들만 보기 때문에 Projectivity가 큰 table에 사용하는 것이 좀 더 유리합니다. 그리고 로딩 시 어느 정도 압축이 되어야 하는지, 몇 개가 들어가야 적정 압축인지를 확인하기 위해서 압축과 해제를 반복하게 되는데, 압축률이 일정하면 이 재압축 횟수가 줄어들게 됩니다. 그래서 로딩속도가 향상된다는 것을 참고 해주시면 됩니다.
3.5. IORM

마지막으로 IORM 같은 경우에는 따로 넣은 이유가 Plan을 먼저 설정해야 되기 때문입니다. 그래서 위에서처럼 Plan 을 설정하게 되면, DB이름으로서 설치가 되는데 db0에 32 share를 주고, db1에는 1을 준다, 이렇게 보시면 됩니다

여러 job들이 들어왔을 때, 분류를 해서 32개, 1개, 32개, 1개의 job을 순서대로 수행합니다. 기본적으로 storage_processing = Y; 를 켜고 Full Scan하게 되면, Function Offloading 때문에 알아서 job이 나뉘게 됩니다.

그렇지 않을 경우, 여러 Session을 열어서 계속 조회해보면 IORM에 대한 성능을 확인하실 수 있습니다. 그런데 32, 1이라고 해서 performance가 정확하게 32 : 1, 이렇게 나오는 것은 아닙니다. 부하가 감당할 수 없을 만큼 들어왔을 때부터 큐잉하기 때문에 정확히 32 : 1이 나온다는 것은 아니라는 점에 유의해주세요.
4. 질의응답
Q. Function Offloading에서 query의 Plan이 어떻게 달라지나요?
A. 기존과 달리 storage_processing = Y; 로 Plan이 찍게 되면 Smart Full Scan 이 출력되는 것을 확인하실 수 있습니다.

Q. Storage Data Map은 어떤 type에 대해 제공이 가능한가요?
A. LOB과 같이 따로 Index로 지정해서 다른 곳에 저장하지 않는 경우를 제외하고는, 모든 타입에 대해서 가능합니다.
Q. 숫자 타입만 되는데, Y는 이런 것들로 필터링할 수 있나요?
A. 네, 정규 형태로 바꿔서 하는 것이기 때문에 따로 타입에 대한 제약조건은 없습니다. LOB에 대해서만 적용이 안 된다고 생각하시면 됩니다.
Q. 거의 모든 영역들이 전체 Min, Max 값을 가지고 있다면 Storage Map을 사용하는 효과가 없을 것도 같습니다.
A. 들어가는 데이터가 sorted 형태면 좋겠지만, DB에서는 그런 개념이 없으니까 index를 생성하는 granule을 조절하여 어느 정도 해결할 수 있습니다. 예를 들어 설명하면, granule을 4Mb로 했을 때, 4Mb라는 영역 안에 들어가는 데이터는 한계가 있기에 Min값과 Max값이 전체적으로 모두 같지는 않을 겁니다. granule를 줄일수록 메모리는 더 많 이 사용할 수 있는 대신, index의 차이를 크게 낼 수 있습니다. 그것은 파라미터로 설정할 수 있습니다.
Q. Storage Data Map에서 대상 column이 많을 경우 최대 8개까지 가능하다는 얘기가 table 나누는 건데, table 개수에 대한 제한은 없는 건가요? 그러니까 table 당 8개는 이해가 되는데, 모든 table에 대해서 적용되는 건가요?
A. Storage Data Map을 생성하는 단위는 table이 아니라 disk의 영역입니다. 그 안의 schema는 DB가 알려줍니다. Storage Server는 table schema를 전혀 모르고, DB가 schema를 알려주는 겁니다. disk 영역에 I/O을 해서 DB가 전해주는 schema를 가지고 Storage Data Map을 형성하 는 형태인 거죠. 그래서 table 개수나 형태 등은 전혀 상 관이 없습니다. 참고로 말씀드리면, 저기서 8개라는 단위 는 where절에 들어가는 column의 개수입니다.

Q. where절에 들어가는 것은 어떻게 보면 schema의 table라는 말인 거잖아요?
A. Storage Data Map은 2Mb든, 4Mb든 Index를 구하는데, 2개의 Storage Data Map 덩어리들은 서로 전혀 관계가 없습니다. 읽으려고 할 때 읽으려는 영역에 대한 schema는 DB가 알려줍니다. 그러니까 schema에 대한 정보는 Storage Server에 저장이 안 되어 있어서, DB가 읽으려고 할 때 schema까지 정해줘야 합니다.
Q. 데이터들이 관리하는 memory size의 한곗값인지 이런 것들 때문에 질문을 드렸습니다. 따로 관련 식이 있는지 궁금합니다.
A. Memory size 설정 부분이 LRU라고 해서 제일 사용빈도가 낮은 것을 빼게 되어있습니다. Default는 전체 설정한 share의 절반 정도를 쓰게 되어있고요. 그런데 계산을 해보면 다 채우기가 쉽지 않습니다. 왜냐하면 4Mb당 몇 byte 밖에 되지 않기 때문에 메모리가 크지 않아도 대부분의 데이터를 다 올릴 수 있습니다.
Q. 저것을 적용할 수 있는 column은 사용자가 따로 지정할 수 있어요? 아니면 DB가 알아서 지정하나요?
A. 현재 그런 기능은 없습니다. query의 where절에 있는 column을 자동으로 지정됩니다.
Q. 이 table에 대해서는 해당 기능을 끄거나 table의 부분적으로 적용하고 싶다, 이렇게 표현할 수는 없는 거예요?
A. 네. 현재는 그런 기능이 없지만, 추후에는 가능할 것 같습니다.
Q. 말씀하신 것처럼 적용하면 오히려 누적으로 오버헤드가 발생하지 않나요?
A. Storage Data 기능은 Function Offloading의 subset입니다. Function Offloading은 어차피 테이블 schema를, where절 에는 로우필터링을 수행해야 하기 때문에 데이터를 분석합니다. Function Offloading 기능을 수행하면, 로우필터링을 하기 위해서 where절을 적용하는데, 그 때 Min, Max값을 계산 해놓을 수 있습니다. 그래서 그것을 메모리에 올려놓 는 것이 조금 아까울 수 있지만, 실제로 몇 Mb당 몇 byte 정도로 index 사이즈가 작으므로 큰 손해는 없습니다.
Q. TAS Instance 생성시, failgroup 부분에 정리해놓은 disk 사이즈가 동일해야 하는지, 달라도 된다면 어떤 차이가 있는지 궁금합니다.
A. 같지는 않아도 됩니다. TAS 전체에서 용량이 두 배, 한 배, 한 배 이렇게 되면 TAS가 input을 할 때 1,2,3,1 이런 식으로 들어갈 수 있도록 합니다. TAS쪽에서 아주 잘 관리하고 있습니다.

Q. 그럼 많은 쪽에서 장애가 나면 어떻게 되나요? 많은 비율을 가지고 disk 쪽에서 설명해주세요.
A. 예를 들어서, Storage Server가 3대가 있고, failgroup을 3개로 지정하여, 3 Way Mirroring을 했을 때는 어쩔 수 없이 제일 작은 Storage Server 용량 밖에 사용할 수가 없습니다. 왜냐하면 데이터를 저장할 때 반드시 각각 Server에 한 개씩 들어가야 하므로 용량의 합이 제일 작은 Server 이상을 저장할 수가 없습니다.
Q. 방금 말씀하신 내용을 전달 해주셨으면 더 좋을 것 같습니다.
A. 그런데 예를 들어서, 2 Way Mirroring이 있고, 3번째 failgroup이 다른 Server보다 두 배 크다면, 전체 영역을 다 쓸 수 있습니다. 대신, Mirroring을 3번째 Storage Server에는 다 들어가 있고, 나머지 반을 반씩 해야 합니다. 이것은 TAS 기능이고, TAS에서는 failgroup별로 전체 용량을 밸런스에 최대한 맞춰서 사용하고 있습니다. 물론, 완전히 끝자리까지는 못 맞추기 때문에 100% 다 쓸 순 없습니다. 조금씩 사이즈 차이가 있으면 약간 남는 공간을 제외하고는 최대한 밸런스를 맞춰서 사용하고 있습니다.
Q. Flash Cache에 올렸다가 Cache out 나지 않도록 특정 table을 딱 고정해주는 기능도 있어요?
A. 기능을 추가하려고 노력하고 있습니다.
Q. Storage Server의 install 환경에 대해서 다시 한번 말씀 해주세요. 특히, 설치와 Instance 생성 부분이요.
A. 각각의 disk들을 storage disk라고 하는데, 각각의 disk들 을 등록하게 되는 것이 위에서 세 번째 줄입니다. “create storage disk SD00”가 SD00로 disk를 등록한다는 의미입니 다. udev rule로 생성된 zeta-disk0를 추가하고 3350G 크기 를 할당하겠다고 하는 의미입니다. 앞서 설명해드렸던 것 처럼, size는 따로 기입하지 않으면 최대 size로 들어가게 됩니다.

이렇게 storage disk로 등록한 후, 아래에서 등록된 storage disk들을 가지고 grid disk를 생성하게 됩니다. grid disk는 TAS 쪽에서 Storage Server의 disk를 등록하는 부분에서처럼 외부에 보이는 disk 형태가 grid disk라고 생각하시면 됩니다.
이 부분에서 중간에 mapping 한번이 불필요할 것처럼 보이잖아요? 원래의 목적은 Storage Disk라고 하는 부분은 Storage Server에서 보는 disk이고, grid disk라고 하는 부분은 TAS map 쪽에 보여주는 disk였습니다. 필요 없을 것 같 지만, 최초에 만든 목적은 같은 hard disk에서도 속도가 다르다는 것을 반영하여 storage disk를 offset별로 잘라서 grid disk 여러 개로 나눠서 쓰려고 한 목적으로 mapping 해둔 것 입니다. 하지만, Flash Cache가 들어가게 되면서 의미가 없어졌습니다. 왜냐하면, 기본적인 I/O가 Cache에서 다 되기 때문입니다. 그래서 지금은 단순히 1:1 mapping 으로 사용하고 있습니다.
Q. 커널 파라미터 설정할 때 Shared 메모리를 전체 메모리 양으로 설정하셨는데, 전체를 모두 사용하는 것인가요?
A. 편하게 하려고 설정한 것입니다. 왜냐하면 shared memory 설정을 조금 바꿔가면서 하는데, shared memory 가 작게 되어 있으면 shared memory 설정 늘리다가 커널 파일도 수정해야 되는 불편함을 겪을 수 있기 때문입니다. 그런데 유지할 메모리를 최댓값으로 설정 해놓으면 자유롭게 쓸 수 있습니다. 그렇기 때문에 최대로 잡고 있습니 다. 실제로 저만큼을 다 쓰는 것은 아니고, 실제로 쓰는 양은 tip file에다가 설정합니다.

Q. ZetaData의 Memory 관리와 설정은 어 떻게 되는지 궁금합니다.
A. ZetaData는 Total Shared Memory와 Shared Memory, PGA를 포함한 Memory Target을 설정하게 되어있습니다. 기본적으 로 어떤 비율로 설정해야 하는지 딱 정해진 것은 없고, 부하의 성격에 따라 조금씩 다르게 설정해주면 됩니다. 일반적으로 OLTP에 집중되어있고, cache가 많이 필요한 경우에는 Total Shared Memory를 보통 많이 잡고 있습니다. 이 외에, 분석 query나 sort처럼 메모리를 많이 사용하는 작업이 주인 경우에는 Total Shared Memory를 줄여서, PGA를 많이 쓸 수 있도록 설정을 합니다.
Q. 구체적인 사이트마다 부하나 파일마다 바뀌는 건 알겠습니다. 그런데 만약 아무런 정보 없이 신규 설치를 진행 하게 되면, 다른 곳으로 가게 되는 경우가 많을 텐데, 그 Default가 PGA도 똑같은 비율로 세팅이 되어있는 것인지 궁금합니다.
A. Storage Server 쪽은 부하 등에 크게 달라질 게 없습니다. 전체 Memory size에 대한 어떤 비율로 현재 가이드를 만들려고 하고 있습니다. 우리는 기본적으로 나갈 때 하드웨어 스펙이 정해져 있기 때문에 지금까지는 96Gb짜리 기준으로 90Gb당 Shared Memory 60Gb정도로 설정하는 것을 Default로 쓰고 있습니다. 그런데 스펙이 바뀌면 거기 에 따라서 메모리가 바뀌어야 하는데 현재는 어떻게 바뀌어야 한다고 정해진 것이 없고, 가이드 또한 아직 없습니 다.
Q. TCC 설정 시 기본적으로 티베로가 저장 을 할 때, column 스토어로 바뀌어서 압축 저장하는 것으로 알고 있습니다. 그러면 raw base를 column base로 저장할 때, 일시적으로 그 저장공간만큼 더 쓰이는 것인지 아니면 필요 없는 것인지 궁금합니다.
A. insert 할 때 보통 raw 단위로 들어옵니 다. TCC는 한 raw씩, 그러니까 단 건 insert 로는 압축이 안 됩니다. 한꺼번에 데이터가 bulk로 들어오는 direct passing insert나 direct pass loading을 할 때, raw가 계속 들 어올 텐데 raw 형태로 데이터 들어온 것들을 memory에서 column 단위로 다 쪼개서 저장합니다. column 별로 다 쌓는 거죠. raw 베이스에서 column 베이스로 바꾸는 데 필요한 임시 공간은 memory에서 가져다 쓰는 것이기 때문 에 추가 공간은 disk에 필요하지 않습니다.
Q. 지금은 loading이나 insert를 할 때 바로 TCC 압축될 때를 말씀하셨는데, 이미 저장되어있는 테이블을 이제 TCC 할 경우는요?
A. 기존 table을 복사하는 형태로만 가능합니다. 기존 table은 그대로 있고, 복사하는 형태로 새 table을 만드는 거죠.
Q. 새 table을 만들면 이전 것은 지워도 상관없죠?
A. 네, 지워도 됩니다. 참고로 table 속성을 바꾸는 것은 기존에 있는 데이터를 바꾸는 의미가 아니고, 앞으로 들어올 데이터에 대해서 압축을 하겠다는 의미로 사용됩니다.
Q. CU 단위를 단위로 설정이 가능한가요?
A. 현재는 Block size로 제한되고 있기 때문에 그렇게 설정이 불가능합니다. 4 Block으로 할 지, 2 Block으로 할지, 6 Block으로 할지 등 이렇게만 설정이 가능합니다. raw 단위로 하려면 Block size는 정해져 있는데, 얼마나 압축이 될 지 예상을 할 수 없으므로, 만약에 raw 사이즈 가 커서 10000 raw씩 압축을 한다고 했을 때 CU size 즉, Block size가 굉장히 커질 수 있습니다. 그런데 이 CU Block 들은 제약조건들이 있습니다. 반드시 전체 덩어리같이 여러 Block 으로 되어있으면, 전체 Block이 연속되어야 하고, extent 경계에 걸치면 안 되는 등 여러 가지 제약 조건이 있습니다. 그래서 raw 단위로는 안됩니다. Block size로만 조절할 수 있게 되어 있습니다.

'DB > Tibero' 카테고리의 다른 글
| [Tibero] Partitioning (0) | 2024.01.22 |
|---|---|
| [Tibero] tbrmgr을 이용한 백업 및 복구 (0) | 2023.11.30 |
| [Tibero] 티베로 DBA 교육 (0) | 2023.11.14 |
| [Tibero] TPR 생성 방법 가이드 (0) | 2023.09.01 |
| [Tibero] HA구조, TSC구조, TAC구조 (0) | 2023.08.09 |



