서버 점검 업무는 데이터베이스가 항상 운영 가능한 상태로 유지하기 위한 사전 점검 절차이며, 불가피한 장애 발생 시 신속하게 대처하여 장애 시간을 최소화 하기 위한 업무이다.
정기점검 대상
라이선스 정보를 가져오는 쿼리와 , vt_version에서 바이너르 정보와 sys._ dd_props NLS_ 캐릭터셋 정보와 v$database에서 db 명 , 로그모드 , db 생성일자와 vt_instance 에서 인스턴스명 상태를 가져옵니다 .
1. TSM Info
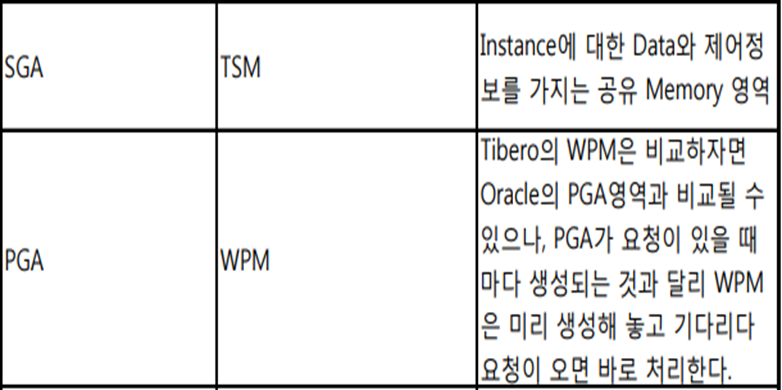
v$sga와_vt_parameter에서파라미터MT값과shared memory값을 가져와서뺀게WPM값입니다. v_sga에서Shared memory total값이TSM,&shared pool memory total값이shared cache size, _vt_parameter에서db_cache_size value값이 버퍼 사이즈,db_block_size값이 블록사이즈, log_buffer값이 리두로그버퍼 사이즈인것을 확인할 수 있습니다.Cache란?? 자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다. 아래와 같은 저장공간 계층 구조에서 확인할 수 있듯이, 캐시는 저장 공간이 작고 비용이 비싼 대신 빠른 성능을 제공한다.
Tibero Shared Memory파트입니다. 해당 부분은 나중에 점검할 캐시 히트율과도 밀접한 관계가 있는데,왜 캐시 히트율이 중요한지 적어두었습니다. DISK I/O 속도(기계적 동작)가 상대적으로 캐시 속도(전기적 동작)보다 현저히 느리기 떄문입니다.
블록 사이즈는 통상 8K로 고정해서 만듭니다.효율성( I/P 메모리관리적인 측면에서 오버헤드 최소화) ,타 DB와 호환성 때문입니다.
보통 저희가 티베로설치할떄Memory Target을서버 물리메모리의 50~60% 선으로 할당하고,TSM을 MT의 절반으로 할당합니다.
2. DB performance
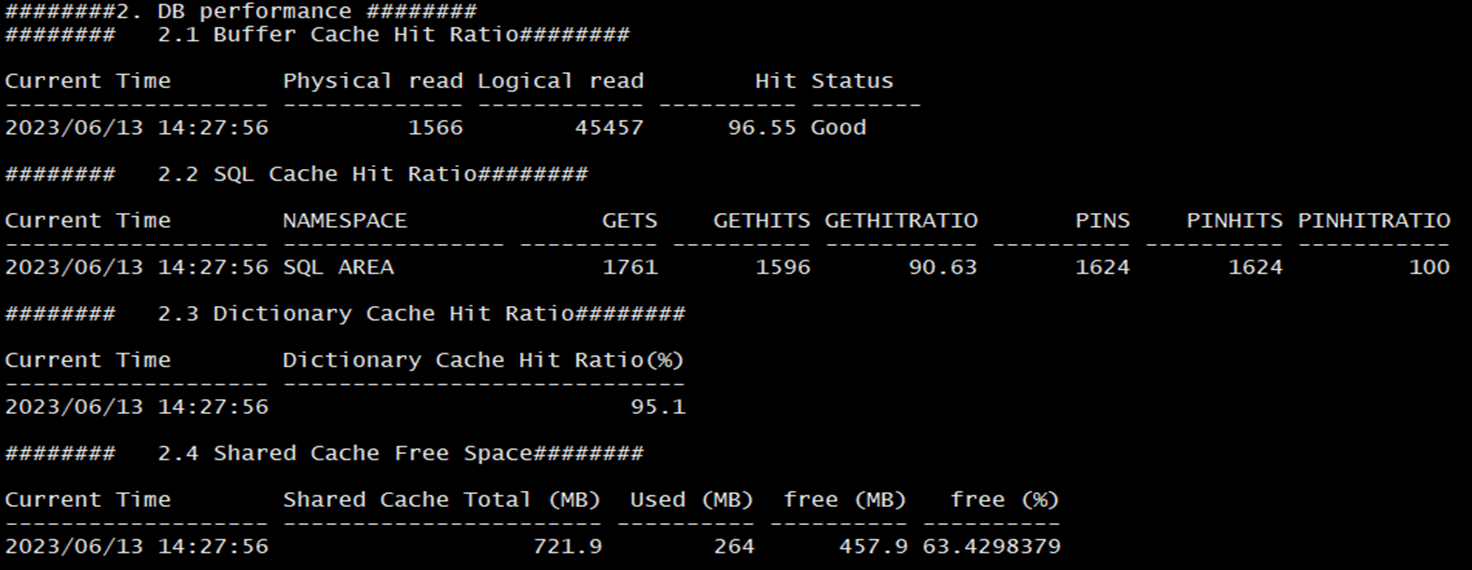
DB성능점검입니다. 제 경험상 테스트 서버의 경우는 버퍼 캐시 히트율이 낮게 나오는 경향이 있습니다. 아무래도 주기적으로 도는 배치잡과 같은 노이즈가 적기떄문에 개발자가 사용하는 쿼리의 영향을 많이 받는거 같습니다. 각 항목에 대한 자세한 설명인 뒤에서 진행하겠습니다.
2.1 Buffer Cache Hit Ratio
v$sysstat 에서 block disk read와 multi block disk read 값을 읽어와 더해준 값이 물리적 읽기 시간입니다. Consistent block gets와 consistent multi gets와 current block gets를 더한값이 논리적 읽기 시간입니다. Hit율은 물리적 읽기시간 / 논리적 읽기시간 입니다.
클라이언트가db에 정보를 요청했을때 아키텍처입니다. 우선 버퍼 캐시를 찾은후 해당 내용이 없으면, 디스크에서 읽어오고 버퍼캐시에 새로운 내용을 적재합니다. 통상 교체 알고리즘은 LRU 알고리즘 입니다.
2.2 SQL Cache Hit Ratio
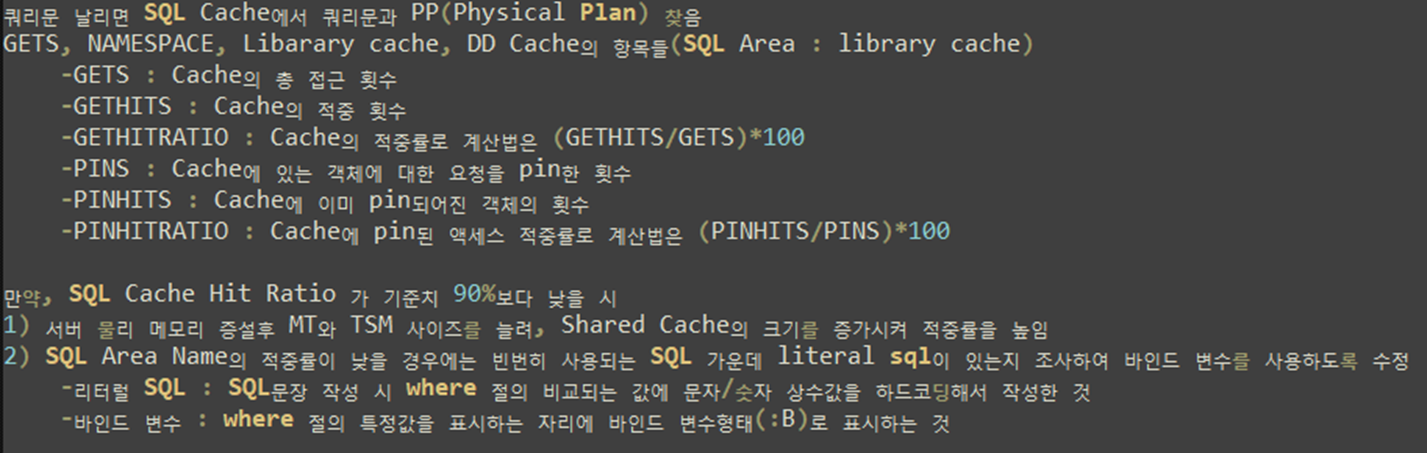
V$librarycache 에서 SQL 영역에서 값들을 가져옵니다 .
Pin이란 실행계획을 고정한다는 의미입니다. 동일 쿼리를 다른세션에서수행시 실행 계획이 변경되지 않도록 고정합니다.
동일 쿼리 실행횟수는 적으나 빈번하게 사용되는 리터럴 쿼리를 찾는 내용입니다.
2.3 Dictionary Cache Hit Ratio
V$rowcache 에서 hit 횟수에 miss 횟수를 뺸값을 hit 횟수로 나눈게 DD 히트율입니다.
2.4 Shared Cache Free Space
v$sga에서 shared pool memory 의 total 값과 used 값을 가져오는 쿼리입니다.
3. Space Usage
테이블 스페이스 여유공간을 점검합니다. 또한 Undo 테이블스페이스 크기가 적절한지도 점검합니다.
3.1Tablespacefree space
DBA_FREE_SAPCE 와 DBA_DATA_FILES 라이트 조인 에서 file_id가 같은것만 데이터 파일이름을 가져오며, DBA_FREE_SPACE의 Bytes 더한값이 null 이면 DBA_DATA_FILES Bytes 더한 값 = USED,null이아니면 이면 DBA_DATA_FILES Bytes 더한 값 - DBA_FREE_SPACE의 Bytes 더한값 = USED 로 판단합니다.
아래와 같이 Tool에서 확인하고, 변경하는 방법도 있습니다.
3.2 Undo Segment Usage
dba_rollback_segs 에서 segment_id, tablespace_name, status 가져오고 v$rollstat 에서 extents, curext, cursize, xacts를 가져옵니다. _vt_parameter 에서 DB_BLOCK_SIZE 값을 가져오고 해당값과 v$rollstat 에서 rssize 를 곱해줘 rssize 값을 구합니다.
4. DISK I/O
DISK I/O 점검입니다. TOTAL I/O가 집중되어있지않는지, AVG_TIME이 1미리세크를 넘지 않는지 점검합니다.
4.1 File I/O Contention
v$DATAFILE 과 v$FILESTAT 에서 file# 과 file# 이 같으면서 v$datafile 과 dba_data_files 에서 file과 file_id# 이 같은 조건에서 테이블스페이스명, 데이터파일명, 물리적읽기수, 물리적쓰기수, 물리적 읽기 퍼센트(물리적 읽기 / 물리적읽기 합 * 100) , 물리적 쓰기 퍼센트( 물리적 쓰기 / 물리적 쓰기 합), 토탈 I/O( 피지컬 리드스 + 피지컬라이트스 물리적 읽기 합 + 물리적 쓰기 합 ), AVG_TIME 을 보여줍니다.
4.2 Online Redo Log switch Count
로그 스위치시 아카이브 파일이 생성되기떄문에 v$archived_log 에서 가져온 first_time 값으로 카운트를합니다. 노아카이브 모드에서도 해당 쿼리로 조회시 확인이 되는것으로 보아, 아카이브 파일만 생성이 안될뿐 v$archived_log 내에 값은 변하는거 같습니다.
5. Current session info
세션 점검입니다. 세션이 풀나면 더 이상 신규 세션 생성이 안되는 장애가 발생하기떄문에 점검합니다._vt_parameter 에서 _wthr_per_proc 값과 wthr_proc_cnt 곱한값이 max값이며 v$sessio에서 상태가 ready인것의 pga_used_mem 더한값이 pga 값, statu가 ready인것과 runnin인것 모두 더한게 total session, 그리고 sess_recoverin중인게 recover session 입니다.
총 세션의 상당수가 Running 세션이라면 Lock과 Current 트랜잭션 정보를 확인하여 적절한 조치를 한다.
tbadmin tool을 사용한 확인입니다.
6. System Resource Usage
서버 CPU 가100 치면 장애가 발생하기떄문에 점검합니다 .
리눅스 환경
윈도우 환경
6.1 Current CPU Usage
6.2 Current Memory Usage
_vt_parameter 에서 MT 이면서 v$sga에서 shared memory 인 조건에서 MT 값 TSM = WPM이라하며 v$session 에서 WTHR(워킹프로세스)가 PGA_USED_MEM 을 PGA라고 합니다.오라클과 티베로에서 용어 차이입니다.
6.3 WTHR count
현재 살아있는 프로세스 개수와 티베로부팅시 즉 설정된 개수가 동일한지 확인합니다.
7. File System Check
파일 시스템 점검입니다. 디스크가 풀차면 장애가 발생하기떄문에 점검합니다.Df 명령어를 이용하여 점검합니다. dba_data_files 와 dba_segments 의 bytes 값을 합해 토탈값과 사용값을 보여줍니다.아카이브가 디스크 풀차면 DB가 멈춘다. 리두로그 스위치할때 아카이브 경로로 파일이 떨어져야하는데, 못떨구니깐 초기화를 하지 못하여 시스템이 멈춰버린다.
8. Alter Log
우선 sys 로그에서 주요 에러들을 검색합니다. 통상 3개월 이내치 에러들만 확인합니다. 앞서 확인못했던 undo 부족에러도 확인해줍니다.
장애 발생 -> tbsvr.out파일 발생 -> 해당 파일보고callstack찾기 방식입니다.
Call stack은 프로세스가 어떤 특정 함수를 호출하면서 장애가 발생하였는지 찾기위해 분석됩니다.
IMS에서 똑같은 callstack을 가진 이슈를 찾아, 동일 이슈인지 판단할수있으며, 유사 사례가 없을시 새로운 IMS를 진행하여 연구원들에게 분석을 요청합니다.
TID (Thread ID): TID는 스레드 식별자(Thread Identifier)를 나타냅니다.
스레드는 프로세스 내에서 실행되는 독립적인 실행 단위입니다. 각 스레드는 고유한 식별자인TID를 가지며, 이를 사용하여 스레드를 식별하고 관리합니다.
OS_THR_ID (Operating System Thread ID): OS_THR_ID는 운영 체제 스레드 식별자를 나타냅니다.
운영 체제는 각 스레드에 대해 고유한 식별자를 할당하며, 이를 OS_THR_ID로 표시합니다.
OS_THR_ID는 운영 체제 수준에서 스레드를 식별하는 데 사용됩니다.
PID (Process ID): PID는 프로세스 식별자(Process Identifier)를 나타냅니다. 프로세스는 실행 중인 프로그램의 인스턴스를 나타내며, 각각은 고유한 PID를 가지고 있습니다. PID를 사용하여 프로세스를 식별하고 운영 체제에서 관리합니다.
OS툴 이용한 모니터링(PSTACK)
서버 프로세스의 비정상적인 I/O 문제나 행(Hang) 문제를 분석하기 위한 용도로 종종 사용됩니다.